Deep Learning với Tensorflow Module 2 Phần 1: Xây dựng mô hình phân loại trong Neural network - Mô hình 2 class (binary class)
Để có thể xem chi tiết toàn bộ quá trình thực hiện của phần này, bạn nên xem trên notebook | https://github.com/mthang1801/deep-learning/blob/main/docs/02_neural_network_classification_in_tensorflow.ipynb
Classification (phân loại) trong machine learning là xây dựng mô hình dự đoán một đối tượng nào đó trong danh sách các đối tượng đã biết trước.
Ví dụ :
* Dự đoán một người có bị bệnh tim mạch hay không dựa trên các chỉ số sức khỏe. Mô hình dự đoán này chỉ gồm 2 option là có hoặc không nên còn được gọi là mô hình nhị phân 2 class (binary class)
* Dự đoán một đối tượng trong ảnh là thức ăn, con người hay đồ vật... Mô hình dự đoán gồm 3 options trở lên còn được gọi là phân loại nhiều class multi-class classification/
* Dự đoán giống chó trong một bức hình chụp một một hoặc nhiều giống chó... Mô hình dự đoán được gọi là multi-label classification vì nó phân loại những giống chó khác nhau trong một thực thể gọi chung là chó.
Nội dung chính mà bài viết sẽ lược qua như sau :
- Kiến trúc của mô hình phân loại (Classification model)
- Tạo dữ liệu mẫu và quan sát
- Kích thước dữ liệu nhập/ xuất (input shapes and output shapes)
X: Biến giải thích, cung cấp thông tin mô tả đối tượng trong dữ liệu (input)y: Biến phụ thuộc, là giá trị cho thấy đối tượng đó thuộc loại nào (label/ output)
Các bước xây dựng mô hình 2 class (binary class) và nhiều class
- Khởi Tạo mô hình
- Compile mô hình
- Định nghĩa loss function
- Thiết lập optimizer
- Tìm kiếm learning_rate tốt nhất
- Tạo evaluation metrics
- Fit mô hình (Bắt đầu train mô hình và tìm kiếm mô hình phù hợp cho dữ liệu)
- Cải thiện mô hình
Tìm hiểu sức mạnh của mô hình phi tuyến tính
Đánh giá mô hình phân loại
- Quan sát mô hình trên đồ thị
- Quan sát độ chính xác và độ sai sót của train, valid.
- So sánh giá trị dự đoán với giá trị thực tế
- Thử nghiệm với tập dữ liệu lơn hơn (Fashion-MNIST)
- Kết luận
1. Kiến trúc của mô hình phân loại (Classification model)
Kiến trúc của mô hình phân loại trong neural network rất đa dạng tùy thuộc vào vấn đề cần giải quyết. Tuy nhiên, trong những kiến trúc đó, chúng có điểm tương đồng cơ bản như sau :
- Một Input layer
- Một vài hidden layer
- Một output layer
Phần lớn khác nhau còn lại tùy thuốc vào nhà phân tích dữ liệu tạo ra mô hình.
Dưới đây là một số tiêu chuẩn mà bạn sẽ thường sử dụng cho mô hình phân loại trong neural network.
| Hyperparameter | Phân loại 2 class (binary class) | Phân loại nhiều class (multi-class) | |||
|---|---|---|---|---|---|
| Input layer shape | Có cùng số biến giải thích (VD : Dự đoán bệnh nhân có bị tim mạch hay không dựa trên 5 đặc tính độ tuổi, giới tính, chiều cao, cân nặng, môi trường sống) | Giống với binary class | |||
| Hidden layers | Điều chỉnh tùy thuộc vào vấn đề, min=1, max= vô hạn | Giống với binary class | |||
| Neurons trên hidden layer | Điều chỉnh tùy thuôc vào vấn đề, Thường từ 10 đến 100 | Giống với binary class | |||
| Output layer shape | 1 ( vì chỉ có 2 class nên chỉ có thể là class này hoặc class kia) | Dựa vào số class (VD : 3 cho food, dog, photo) | |||
| Hidden activation | Thường là ReLU (rectified linear unit) | Giống với binary class | |||
| Output activation | Sigmoid | Softmax | |||
| Loss function | Cross entropy (tf.keras.losses.BinaryCrossentropy trong TensorFlow) | Cross entropy (tf.keras.losses.CategoricalCrossentropy trong TensorFlow) | |||
| Optimizer | SGD (stochastic gradient descent), Adam | Giống với binary class |
Table 1: Typical architecture of a classification network. Source: Adapted from page 295 of Hands-On Machine Learning with Scikit-Learn, Keras & TensorFlow Book by Aurélien Géron
2. Tạo dữ liệu mẫu và quan sát
Chúng ta có thể bắt đầu bằng cách nhập tập dữ liệu phân loại nhưng hãy thực hành tạo một số dữ liệu phân loại của riêng mình
Vì mô hình phân loại được xây dựng để dự đoán một đối tượng nào đó là cái này hoặc cái kia nên chúng ta hãy tạo một số dữ liệu phù hợp để phản ánh điều đó.
Để làm được điều này, chúng ta sẽ sử dụng hàm trong Scikit-Learn's make_circles().
from sklearn.datasets import make_circles # Tạo 5000 mẫu n_samples = 1000 X,y = make_circles(n_samples,noise=0.02,random_state=42)
X[:5]
array([[ 0.76026594, 0.22387823], [-0.76722217, 0.1455425 ], [-0.80815854, 0.14894355], [-0.3760283 , 0.70320906], [ 0.44051035, -0.89761737]])
y[:5]
array([1, 1, 1, 1, 0])
Chúng ta đã thấy 5 phần tử đầu tiên của X và y. Nhưng nó chỉ là những ma trận nên rất khó để quan sát trực quan. Do đó
Một điều quan trọng khi bắt đầu thực hiện các dự án machine learning là chúng ta cần thích nghi với mô hình. Và một trong những cách tốt nhất để có được điều đó là quan sát dữ liệu bằng cách tạo đồ thị càng nhiều càng tốt.
import pandas as pd
circles = pd.DataFrame({"X1" : X[:,0], "X2" : X[:,1], "label" : y}) circles
| X1 | X2 | label | |||||
|---|---|---|---|---|---|---|---|
| 0 | 0.760266 | 0.223878 | 1 | ||||
| 1 | -0.767222 | 0.145542 | 1 | ||||
| 2 | -0.808159 | 0.148944 | 1 | ||||
| 3 | -0.376028 | 0.703209 | 1 | ||||
| 4 | 0.440510 | -0.897617 | 0 | ||||
| ... | ... | ... | ... | ||||
| 995 | 0.241536 | 0.953294 | 0 | ||||
| 996 | -0.975298 | -0.264479 | 0 | ||||
| 997 | -0.141235 | -0.801951 | 1 | ||||
| 998 | 0.675090 | -0.754657 | 0 | ||||
| 999 | 0.282378 | 0.962057 | 0 |
1000 rows × 3 columns
Số lượng các label đang làm việc
circles.label.value_counts()
1 500 0 500 Name: label, dtype: int64
circles có 2 label là 0 và 1, mỗi label đều có 2500 giá trị -> Đây là mô hình 2 class (binary class)
Nếu như có nhiều hơn 2 labels (chẳng hạn 0,1,2,3,4...) thì đó là mô hình nhiều class
import matplotlib.pyplot as plt
plt.scatter(X[:,0],X[:,1],c=y, cmap=plt.cm.RdYlBu)
<matplotlib.collections.PathCollection at 0x7f46cd316550>

Từ đồ thì, chắc hẳn bạn đã đoán được chúng ta sắp xây dựng mô hình nào rồi đúng không ?
Làm thế nào về việc chúng ta có thể một mô hình để phân loại các chấm màu xanh với chấm đỏ? Như trong mô hình có thể phân biệt màu xanh lam với các chấm màu đỏ.
🛠 Luyện tập: Trước khi tiến hành những bước tiếp theo, bạn có thể dành 10 phút để trải nghiệm Tensorflow Playground. Thử chỉnh các hyperparameter khác nhau mà bạn nhìn thấy và cloci vào nút Play để xem các đường neural.
3. Kích thước dữ liệu nhập/ xuất (input shapes and output shapes)
Một trong những vấn đề thường gặp nhất khi bạn tiến hành chạy mô hình neural network là kích thước (shape) không phù hợp. Cụ thể hơn là kích thước của dữ liệu nhập và xuất. Trong trường hợp này là chúng ta muốn input X và tạo mô hình để dự đoán y. Chúng ta sẽ cùng kiểm tra kích thước của 2 biến này.
X.shape, y.shape
((1000, 2), (1000,))
X: 1000 dòng, 2 cộty: 1000 dòng
Chúng ta sẽ kiểm tra phần tử đầu tiên của X và y
X[0], y[0]
(array([0.76026594, 0.22387823]), 1)
Vậy là chúng ta có 2 thuộc tính của X để giải thích cho giá trị của y.
Điều này có nghĩa là kích thước đầu vào neural network của chúng ta sẽ phải chấp nhận một tensor với ít nhất một chiều là hai thuộc tính và trả về một tensor có ít nhất một giá trị
Lưu ý:
ycó kích thước (1000,) có thể gây nhầm lẫn. Tuy nhiên, điều này là vì tất cả các giá trị củaythực sự là giá trị đơn (scalar) và do đó, chúng không có chiều. Từ giờ đây, khi nghĩ đến kích thước của giá trị xuất thì ít nhất nó cũng phải có cùng kích thước như củay( trong trường hợp này, giá trị xuất ra từ neural network phải có ít nhất 1 giá trị )
4. Các bước xây dựng mô hình 2 class (binary class) và nhiều class
Bây giờ chúng ta đã có dữ liệu gì cũng như kích thước đầu vào và đầu ra. Điều tiếp theo là xây dựng mô hình dự đoán.
Trong Tensorflow, có 3 bước cơ bản để xây dựng mô hình :
- Tạo mô hình (Creating model) : Nối các layers trong neural network lại với nhau ( sử dụng functional or sequential API) hoặc import mô hình đã được train trước đó (transfer learning)
- Compile mô hình (Compile model): Định nghĩa hiệu suất mà mô hình nên đo lường (loss/metrics) cũng như làm như thế nào để cải thiện mô hình đó (optimizer)
- Fit mô hình: Mô hình cố gắng tìm kiếm các khuôn mẫu (các điểm tương đồng hoặc có mối liên hệ) trong dữ liệu (hay nói khác là làm như thế nào để biến các đặc tính
Xthànhy)
# Import libraries import tensorflow as tf from tensorflow.keras import Sequential from tensorflow.keras.layers import Dense
model_1
tf.random.set_seed(42) model_1 = Sequential() model_1.add(Dense(1)) model_1.compile( loss="binary_crossentropy", optimizer="sgd", metrics=["accuracy"] ) model_1.fit(X,y, epochs=5)
Epoch 1/5 32/32 [==============================] - 1s 5ms/step - loss: 3.4729 - accuracy: 0.4524 Epoch 2/5 32/32 [==============================] - 0s 5ms/step - loss: 0.7390 - accuracy: 0.5030 Epoch 3/5 32/32 [==============================] - 0s 3ms/step - loss: 0.7218 - accuracy: 0.4687 Epoch 4/5 32/32 [==============================] - 0s 4ms/step - loss: 0.6965 - accuracy: 0.5089 Epoch 5/5 32/32 [==============================] - 0s 3ms/step - loss: 0.6956 - accuracy: 0.4883
<tensorflow.python.keras.callbacks.History at 0x7f46b0945130>Từ kết quả trên, ta thấy được độ chính xác, độ sai sót của mối epoch trong quá trình train. Mô hình thực hiện có vẻ không tốt (độ chính xác < 50%). Nhưng nếu train lâu hơn, mô hình có cải thiện không ?
model_1.fit(X,y, epochs=100,verbose=0) model_1.evaluate(X,y)
32/32 [==============================] - 0s 3ms/step - loss: 0.6932 - accuracy: 0.5000
[0.6932448744773865, 0.5]model_2
Dù đã tăng số lần train lên 100 nhưng độ chính xác của mô hình vẫn không tăng được nhiều. Vậy nếu như tăng số layer trong mô hình, liệu nó có cải thiên không ?
tf.random.set_seed(42) model_2 = Sequential() model_2.add(Dense(1)) model_2.add(Dense(1)) model_2.add(Dense(1)) model_2.compile( loss="binary_crossentropy", optimizer="sgd", metrics=["accuracy"] ) model_2.fit(X,y, epochs=5, verbose=0)
<tensorflow.python.keras.callbacks.History at 0x7f4690200340>
model_2.evaluate(X,y)
32/32 [==============================] - 0s 4ms/step - loss: 7.6246 - accuracy: 0.5000
[7.6246185302734375, 0.5]Oh! Vẫn không cải thiện được (chính xác chỉ ~50% )
Làm thế nào để cải thiện mô hình? Ở những bài trước đã có giới thiệu cho bạn những cách cải thiện mô hình được sử dụng rất phổ biến như sau:
- Thêm layer để mô hình học được sâu hơn ( Đôi khi học quá sâu dẫn đến tác dụng phụ làm mô hình kém hiệu quả hơn )
- Tăng thêm số units (neurons) trong mỗi layer
- Thay đổi activation function
- Thay đổi optimization function (
sgd,adam...) - Thay đổi learning rate
- Tăng thêm dữ liệu train
- Train mô hình lâu hơn

model_3 (Cải thiện mô hình)
tf.random.set_seed(42) model_3 = Sequential() model_3.add(Dense(10)) model_3.add(Dense(10)) model_3.add(Dense(1)) model_3.compile( loss="binary_crossentropy", optimizer="adam", metrics=["accuracy"] ) model_3.fit(X,y,epochs=100,verbose=0)
<tensorflow.python.keras.callbacks.History at 0x7f46936e5f70>
model_3.evaluate(X,y)
32/32 [==============================] - 0s 5ms/step - loss: 0.6932 - accuracy: 0.4760
[0.6931796669960022, 0.47600001096725464]Độ chính xác trong dự đoán của mô hình vẫn không được cải thiện. Vẽ đồ thị để quan sát xem có vấn đề gì với mô hình này.
🔑 Lưu ý: Bất cứ khi nào mô hình của bạn hoạt động bất thường hoặc có điều gì đó xảy ra đối với dữ liệu khiến chúng hoạt động không đúng như mong muốn, bạn hãy vẽ biểu đồ để quan sát chúng để kiểm tra dữ liệu của bạn, kiểm tra mô hình của bạn xem chúng được đưa vào các dự đoán của mô hình của bạn như thế nào.
Để quan sát mô hình dự đoán, chúng ta sẽ tạo một hàm vẽ biểu đồ có tên plot_decision_boundary() với:
- Lấy trong mô hình train các đặc tính X và label y
- Tạo meshgrid cho các đặc tính X khác nhau
- Đưa ra dự đoán thông qua meshgrid.
- Vẽ đồ thị dự đoán cũng như các đường thẳng giữa các vùng khác nhau ( nơi chứa các class riêng biệt)
Nghe có vẻ hơi khó hiểu, nhưng không sao bạn cứ xem những dòng code dưới đây sẽ trực quan hơn.
🔑 Lưu ý : Nếu như bạn không chắc chắn về những gì mô tả trong hàm, bạn hãy thử nó riêng lẻ để xem ý nghĩa của nó như thế nào, rồi sau đó hãy ghép nó vào trong hàm.
Tạo hàm vẽ đồ thị của mô hình dự đoán
import numpy as np import matplotlib.pyplot as plt
def plot_decision_boundary(model, X,y) : """ Vẽ decision boundary được tạo bởi mô hình dự đoán trên đặc tính `X`, Hàm này được phỏng theo từ nguồn : 1. CS231n - https://cs231n.github.io/neural-networks-case-study/ 2. Made with ML basics - https://github.com/GokuMohandas/MadeWithML/blob/main/notebooks/08_Neural_Networks.ipynb """ # Định nghĩa giá trị giới hạn trục x và y x_min, x_max = X[:,0].min(), X[:,0].max() + 0.1 y_min, y_max = X[:,1].min(), X[:,1].max() + 0.1 xx,yy = np.meshgrid(np.linspace(x_min,x_max,101), np.linspace(y_min, y_max,101)) # Tạo X dựa trên các giá trị xx,yy x_in = np.c_[xx.ravel(),yy.ravel()] # stack 2D arrays together: https://numpy.org/devdocs/reference/generated/numpy.c_.html # Thực hiện dự đoán mô hình train pred = model.predict(x_in) if len(pred[0]) > 1 : print("Đang làm việc với mô hình phân loại nhiều lớp") return else : print("Đang làm việc với mô hình phân loại 2 lớp") pred = np.round(pred).reshape(xx.shape) plt.contourf(xx,yy,pred, cmap=plt.cm.RdYlBu, alpha=0.5) plt.scatter(X[:,0],X[:,1],c=y,cmap=plt.cm.RdYlBu,s=25, edgecolors="k") plt.xlim([x_min,x_max]) plt.ylim([y_min,y_max])
plot_decision_boundary(model_3, X,y)
Đang làm việc với mô hình phân loại 2 lớp

model_3 ( mô hình hồi quy)
Đồ thị trông có vẻ đang vẽ một đường thẳng đi qua dữ liệu. Nhưng mô hình hiện tại của chúng ta không phải là mô hình hồi quy tuyến tính. Nếu đây là mô hình tuyến tính, có thể nó sẽ hoạt động tốt, cùng thử xem :
X_reg = np.arange(0,800,5) y_reg = np.arange(100,900,5) X_reg_len = len(X_reg) y_reg_len = len(y_reg) X_reg_train = X_reg[:int(0.8 * X_reg_len)] y_reg_train = y_reg[:int(0.8 * y_reg_len)] X_reg_test = X_reg[int(0.8 * X_reg_len):] y_reg_test = y_reg[int(0.8 * y_reg_len):] X_reg_train.shape, y_reg_train.shape, X_reg_test.shape, y_reg_test.shape
((128,), (128,), (32,), (32,))
Thử đưa dữ liệu vừa mới tạo vào model_3
model_3 = Sequential() model_3.add(Dense(100)) model_3.add(Dense(10)) model_3.add(Dense(1)) model_3.compile( loss="mae", optimizer="adam", metrics=["mae"] ) model_3.fit(X_reg_train, y_reg_train, epochs=100, verbose=0)
<tensorflow.python.keras.callbacks.History at 0x7f4693435280>
y_preds= model_3.predict(X_reg_test) plt.figure(figsize=(10,6)) plt.scatter(X_reg_train, y_reg_train, label="Trainning") plt.scatter(X_reg_test, y_reg_test, label="Testing") plt.scatter(X_reg_test, y_preds, label="Predicting") plt.legend()
<matplotlib.legend.Legend at 0x7f46933446d0>

Mô hình hồi quy trên dự đoán dù không hoàn hảo (mô hình hoàn hảo khi đường màu xanh trùng với đường màu cam) nhưng nó vẫn tốt hơn mô hình phân loại. Vì vậy, điều này đồng nghĩa với việc mô hình cần học thêm một vài thứ.
model_4 (Mô hình phi tuyến tính)
Chúng ta đã thấy neural network có thể mô hình các các đường thằng với khả năng dự đoán tốt hơn như trên. Vậy nếu mô hình không theo đường thằng, liệu neural network có làm tốt không?
Nếu chúng ta thực hiện mô hình dữ liệu phân loại ( phân loại màu đỏ và xanh của circles), chúng ta sẽ cần một vài đường phi tuyến
🔨 Thực hành: Trước khi đi tiếp, bạn có thể trải nghiệm mô hình phân loại dữ liệu trong TensorFlow Playground, cố gắng thay đổi các hypeparameter tùy ý để xem sự khác biệt giữa giữa chúng.
Chúng tôi sẽ tái tạo neural network mà bạn có thể thấy tại liên kết này:
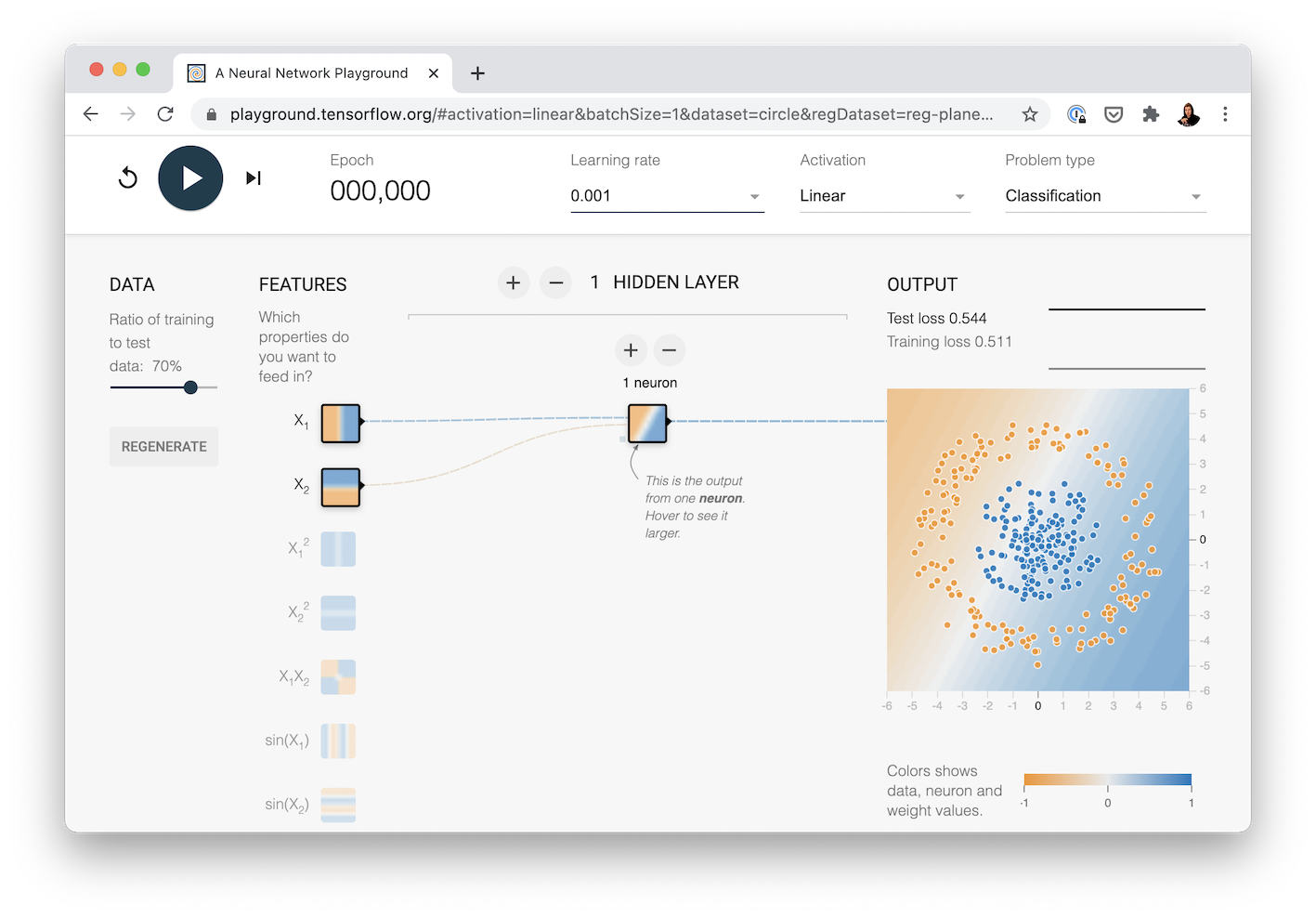
Ý tưởng chính trong mô hình dưới đây là thêm activation function cho mô hình
tf.random.set_seed(42) model_4 = Sequential() model_4.add(Dense(100, activation=tf.keras.activations.linear)) model_4.add(Dense(1)) model_4.compile( loss="binary_crossentropy", optimizer="adam", metrics=["accuracy"] ) model_4.fit(X,y, epochs=100,verbose=0)
<tensorflow.python.keras.callbacks.History at 0x7f46933163a0>
model_4.evaluate(X,y)
32/32 [==============================] - 0s 2ms/step - loss: 0.6942 - accuracy: 0.5090
[0.694219708442688, 0.5090000033378601]plot_decision_boundary(model_4, X,y)
Đang làm việc với mô hình phân loại 2 lớp

Tỉ lệ dự đoán chính xác của mô hình chỉ ở mức ~50% , linear activation function tạo ra một đường thẳng trong dự đoán mô hình, vì linear được áp dụng cho các mô hình tuyến tính trong khi dữ liệu của chúng ta là phi tuyến. Vì vậy, chúng ta sẽ phải thay đổi activation function thành dạng phi tuyến đến mô hình. Và một trong số những activation phi tuyên được sử dụng rất phổ biến là ReLU
5. Tìm hiểu sức mạnh của mô hình phi tuyến tính
model_5 (Thêm activation cho hidden layers của mô hình phi tuyến)
tf.random.set_seed(42) model_5 = Sequential() model_5.add(Dense(5, activation="relu")) model_5.add(Dense(5, activation="relu")) model_5.add(Dense(1)) model_5.compile( loss="binary_crossentropy", optimizer=tf.keras.optimizers.Adam(learning_rate=0.001), metrics=["accuracy"] ) history_5 = model_5.fit(X,y,epochs=100,verbose=0)
model_5.evaluate(X,y)
32/32 [==============================] - 0s 4ms/step - loss: 0.6164 - accuracy: 0.7740
[0.6164438724517822, 0.7739999890327454]plot_decision_boundary(model_5, X,y)
Đang làm việc với mô hình phân loại 2 lớp

model_6 (thêm activation function cho output layer của mô hình phi tuyến)
Mô hình dự đoán đã được cải thiện rất đáng kể ~77% và chúng ta thấy được đồ thị đã không còn những đường thẳng nữa mà nó bắt đầu uốn theo hình dáng của dữ liệu. Đó mới chỉ là thay đổi activation function của các hidden layer, nếu ta thêm activation cho output layer thì liệu mô hình có cải thiện thêm không?
Vì dữ liệu hiện tại chỉ là phân loại 2 class (binary class) nên output layer sẽ là Sigmoid activation function.
tf.random.set_seed(42) model_6 = Sequential() model_6.add(Dense(5, activation=tf.keras.activations.relu)) model_6.add(Dense(5, activation=tf.keras.activations.relu)) model_6.add(Dense(1, activation=tf.keras.activations.sigmoid)) model_6.compile( loss="binary_crossentropy", optimizer="adam", metrics=["accuracy"] ) model_6.fit(X,y,epochs=100,verbose=0)
<tensorflow.python.keras.callbacks.History at 0x7f4693b4b1c0>
model_6.evaluate(X,y)
32/32 [==============================] - 0s 2ms/step - loss: 0.1091 - accuracy: 1.0000
[0.10911206156015396, 1.0]plot_decision_boundary(model_6,X,y)
Đang làm việc với mô hình phân loại 2 lớp

loss , accuracy = model_6.evaluate(X_test,y_test) print(f"Độ chính xác của mô hình : {accuracy*100:.2f}%") print(f"Độ sai số của mô hình : {loss}")
7/7 [==============================] - 0s 10ms/step - loss: 0.1015 - accuracy: 1.0000 Độ chính xác của mô hình : 100.00% Độ sai số của mô hình : 0.10146533697843552
Mô hình có vẻ hoàn hảo sau khi thêm Signmoid activation function vào output layer. Nó tách dữ liệu ra làm 2 miền rõ ràng.
🤔 Nhưng liệu khi chúng ta dự đoán với những dữ liệu mà mô hình chưa được học thì nó có thực sự chính xác như vậy hay không? Nhớ rằng từ đầu bài viết đến giờ, chúng ta chưa hề tách dữ liệu thành
trainvàtestmà dùng toàn bộ dữ liệu để train mô hình. Khi đánh giá mô hình, những dữ liệu được đánh giá đều là những dữ liệu đã được học nên mô hình có thể nhận diện được ngay.
Trước khi trả lời cho câu hỏi trên, chúng ta cần nhận ra những gì mà chúng ta đã làm rằng :
🔑Lưu ý: Sự kết hợp giữa hàm tuyến tính( đường thẳng) và phi tuyến tính( không là đường thẳng) là một trong những nền tảng then chốt trong neural network
Có thể nghĩ như thế này :
Nếu như bạn có vô số đường thẳng cũng như không phải là những đường thẳng, loại mô hình nào bạn có thể vẽ được ?
Về cơ bản, những gì mà neural network làm là tìm kiếm những điểm đặc trưng của các đặc tính trong từng đối tượng trong dữ liệu (pattern) để xây dựng mô hình. Để có được một cái nhìn rõ hơn về các activation function mà chúng ta vừa sử dụng, hãy tạo chúng và sau đó thử chúng trên một số dữ liệu
Cách thức hoạt động của các activation function
tf.keras.activation.linear
Công thức: $f(x)=x$
A = tf.cast(tf.range(-10,10), dtype=tf.float32) plt.plot(A)
[<matplotlib.lines.Line2D at 0x7f465a2edbe0>]

Tuyến tính là một đường thẳng.
tf.keras.activations.sigmoid. có công thức sau :
Công thức : $f(x) = {\frac{1}{1+ e^{-x}}}$
def sigmoid(x) : return 1/ (1 + tf.math.exp(-x))
plt.plot(sigmoid(A))
[<matplotlib.lines.Line2D at 0x7f465a2b1700>]

def relu(x) : return tf.maximum(0,x)
plt.plot(relu(A))
[<matplotlib.lines.Line2D at 0x7f465a26c970>]

Kiểm tra xem hàm activation trong tf có trùng với công thức toán học hay không
tf.keras.activations.linear(A) == A
<tf.Tensor: shape=(20,), dtype=bool, numpy= array([ True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True, True])>
Rõ ràng khi mô hình không học được gì khi sử dụng linear activation function vì bản thân hàm này không thay đổi bất cứ dữ liệu gì. Trong khi đó, với hàm phi tuyến, tất cả dữ liệu đều được xử lý. Neural network sử dụng các phép biến đổi này ở quy mô lớn để tìm các pattern cho input và output.
Để có thể tìm hiểu sâu hơn về các vấn đề này, bạn có thể đọc thêm machine learning cheatsheet page. Riêng đến đây là đủ, chúng ta sẽ tiếp tục xây dựng mô hình dự đoán.
6. Đánh giá mô hình phân loại
Ta đã tiến hành đánh giá mô hình dựa trên dữ liệu đã được học, kết quả độ chính xác hoàn hảo 100%. Nhưng thực sự nó có hoàn hảo đến như vậy? Để đánh giá khách quan một mô hình có tốt hay không, ta cần cho nó nhận diện những gì mà nó chưa từng biết đến, còn những thứ đã học rồi, nó đã thuộc tất cả nên không thể cho rằng là tốt.
Do đó, trước khi đưa dữ liệu vào mô hình, ta cần tách dữ liệu ra làm 2 phần riêng biệt là train và test. Dữ liệu train sẽ là dữ liệu được đưa vào mô hình để nó học, còn dữ liệu test là những dữ liệu mà mô hình chưa hề biết trong quá trình học, sẽ được đưa vào để kiểm tra xem mô hình học như thế nào.
Thông thường dữ liệu train sẽ chiếm 70% - 80%, dữ liệu test từ 20% - 30%
Tách dữ liệu thành train và test thủ công (không shuffle dữ liệu)
# Lấy 80% trong tổng số dữ liệu train_len = int(0.8 * len(X)) X_train = X[:train_len] y_train = y[:train_len] X_test = X[train_len:] y_test = y[train_len:] X_train.shape, X_test.shape, y_train.shape, y_test.shape
((800, 2), (200, 2), (800,), (200,))
OK, dữ liệu hiện tại đã được chia thành train và test, ta sẽ tiến hành xây dựng và đánh giá mô hình
model_7 ( mô hình được chia thành train và test thủ công)
tf.random.set_seed(42) model_7 = Sequential() model_7.add(Dense(5,activation="relu")) model_7.add(Dense(5,activation="relu")) model_7.add(Dense(1,activation="sigmoid")) model_7.compile( loss="binary_crossentropy", optimizer=tf.keras.optimizers.Adam(learning_rate=0.01), metrics=["accuracy"] ) history_7 = model_7.fit(X_train, y_train, epochs=25, verbose=0)
plot_decision_boundary(model_7, X_test, y_test)
Đang làm việc với mô hình phân loại 2 lớp

loss , accuracy = model_7.evaluate(X_test,y_test) print(f"Độ chính xác của mô hình : {accuracy*100:.2f}%") print(f"Độ sai số của mô hình : {loss}")
7/7 [==============================] - 0s 4ms/step - loss: 0.0200 - accuracy: 1.0000 Độ chính xác của mô hình : 100.00% Độ sai số của mô hình : 0.019987007603049278
wow! độ chính xác 100%!
Có thể thấy độ chính xác giữa model_6 và model_7 đều là 100%, vậy 2 mô hình này có gì khác nhau?
activation: Sử dụngsigmoidvàreluthay vì sử dụng dường dẫn đến thư viện nhưtf.keras.activations.relu. Trong Tensorflow, cả 2 đều được hiểu như nhaulearning_rate: Nếu như không có gì thì giá trị mặc định củalearning_ratetrongoptimizerlà 0.001. Nếulearning_ratecàng lớn thì tốc độ học của mô hình càng nhanh. Tuy nhiên, cũng giống như con người, khi mô hình học nhanh quá mức sẽ dẫn đến việc nó không tiếp thu được thứ gì cả. Do đó, ở những mô hình sau sẽ có một số mẹo để tìmlearning_ratetốt nhất.- Số lượng
epochs: Ởmodel_7số epocsh chỉ còn 25 so với 100 trongmodel_6nhưng nó vẫn tạo ra kết quả dự đoán đáng kinh ngạc ở cả tập dữ liệutrainvàtest. Một lý do khiến cho mô hình này thực hiện tốt mặc dù sốepochsthấp hơn là vì chúng ta đã tăng tỉ lệlearning_ratetrongmodel_7, tức là nó học được nhanh hơn (Nhớ rằng mỗi epoch trong mô hình là một cơ hội để mô hình cố gắng tìm kiếm các pattern trong dữ liệu)
Chúng ta biết mô hình của mình đang hoạt động tốt dựa trên các chỉ số đánh giá nhưng hãy xem mô hình hoạt động trực quan như thế nào.
plt.figure(figsize=(16,6)) plt.subplot(121);plot_decision_boundary(model_7, X_train, y_train);plt.axis(False); plt.subplot(122);plot_decision_boundary(model_7, X_test, y_test);plt.axis(False);
Đang làm việc với mô hình phân loại 2 lớp Đang làm việc với mô hình phân loại 2 lớp

Như vậy, chỉ cần một số thay đổi trong activation function, chúng ta đã tạo ra được mô hình dự đoán cực kỳ chính xác
Vẽ loss curves
Từ đồ thị trên chúng ta có thể thấy kết quả đầu ra của mô hình của là rất tốt. Nhưng đó là khi mô hình đã train xong, làm sao để có thể đánh giá được độ chính xác, sai sót, cũng như hiệu suất của quá trình train qua từng giai đoạn (epoch)?
Để tìm ra được điều này, chúng ta có thể kiểm tra loss curves (cũng được biết đến như learning curve)
Ở những module trước, có thể bạn đã từng thấy biến history khi gọi phương thức fitting cho mô hình ( fit() trả về history). Đây là nơi chúng ta sẽ lấy thông tin về cách mô hình hoạt động như thế nào.
Xét module_7, đặt biến history_7 khi gọi phương thức fit cho mô hình này.
pd.DataFrame(history_7.history)
| loss | accuracy | ||||
|---|---|---|---|---|---|
| 0 | 0.690324 | 0.51000 | |||
| 1 | 0.682502 | 0.54875 | |||
| 2 | 0.676075 | 0.56375 | |||
| 3 | 0.666695 | 0.59375 | |||
| 4 | 0.657808 | 0.61375 | |||
| 5 | 0.641272 | 0.62500 | |||
| 6 | 0.615222 | 0.69750 | |||
| 7 | 0.571046 | 0.78250 | |||
| 8 | 0.495315 | 0.94875 | |||
| 9 | 0.401716 | 0.97125 | |||
| 10 | 0.303857 | 0.98875 | |||
| 11 | 0.206910 | 0.99750 | |||
| 12 | 0.143688 | 0.99750 | |||
| 13 | 0.106295 | 1.00000 | |||
| 14 | 0.078821 | 0.99875 | |||
| 15 | 0.063281 | 1.00000 | |||
| 16 | 0.050026 | 1.00000 | |||
| 17 | 0.041818 | 1.00000 | |||
| 18 | 0.036063 | 1.00000 | |||
| 19 | 0.033132 | 1.00000 | |||
| 20 | 0.026972 | 1.00000 | |||
| 21 | 0.024927 | 1.00000 | |||
| 22 | 0.021782 | 1.00000 | |||
| 23 | 0.020625 | 1.00000 | |||
| 24 | 0.018404 | 1.00000 |
Từ bảng trên chúng ta có thể thấy giá trị loss giảm xuống và accuracy tăng lên. Nhưng ta nên biểu diễn chúng dưới dạng đồ thị
pd.DataFrame(history_7.history).plot()

🔑 Lưu ý: Khi quan sát đồ thị, loss giảm, accuracy tăng chứng tỏ mô hình đang cải thiện dần dần. Điều này cũng đồng nghĩa giá trị dự đoán sẽ gần hơn với giá trị thực tế.
Tìm kiếm learning rate tốt nhất
Ngoài các kiến trúc được xây dựng cố định trong mô hình ( như layers, số neurons, activations...) thì hyperparameter quan trọng nhất mà chúng ta có thể thay đổi được trong neural network là learning rate.
Trongmodel_7, bạn đã thấy learning_rate được điều chỉnh ngoài giá trị mặc định (0.001). Lúc đó, có thể bạn sẽ tự hỏi tại sao lại có con số này? Trả lời cho câu hỏi đó là con số ngẫu nhiên từ việc đoán mò mà ra 😎. Tuy nhiên, trong mục này, chúng ta sẽ tìm kiếm learning rate tốt nhất thực sự. Nhưng dù nó là tốt nhất thì cũng không có nghĩa làm bạn hài lòng nhất với kết quả cuối cùng. Do đó, điều quan trọng đó là sự trải nghiệm của bản thân với mô hình, bạn nên xây dựng nó, đánh giá nó, rồi cứ lặp đi lặp lại cho đến khi hài lòng.
Để tìm learning rate tốt nhất, ta sẽ sử dụng callback function là : learning rate callback.
model_8 (xây dựng mô hình và sử dụng learning rate callback function để tìm kiếm learning rate tốt nhất)
tf.random.set_seed(42) model_8 = Sequential() model_8.add(Dense(5, activation="relu")) model_8.add(Dense(5, activation="relu")) model_8.add(Dense(1, activation="sigmoid")) model_8.compile( loss="binary_crossentropy", optimizer="adam", metrics=["accuracy"] ) lr_scheduler = tf.keras.callbacks.LearningRateScheduler(lambda epoch : 1e-4 * 10**(epoch/20)) # Learning rate bắt đầu từ 0.001, Cứ qua mỗi epoch learning rate sẽ tăng dần theo 10^(ep /20) history_8 = model_8.fit(X_train, y_train, epochs=100, callbacks=[lr_scheduler], verbose=0 )
Sau khi mô hình train xong, các giá trị learning rate callback sẽ được lưu lại trong history_8. Nhưng vì history lưu các giá trị của accuracy và loss, vì vậy sử dụng pandas để mở bảng history_8
pd.DataFrame(history_8.history).plot(figsize=(12,6))

Qua biểu đồ có thể thấy tỉ lệ learning rate tăng theo theo hàm mũ khi số epoch tăng. Ở một số điểm cụ thể , độ chính xác của mô hình tăng ( sai sót giảm ) thì learning rate sẽ tăng chậm. Để tìm ra những điểm này ở đâu, chúng ta có thể vẽ biểu đồ loss so với log-scale của learning rate
lrs = 1e-4 * (10**(np.arange(0,100,1) / 20)) plt.figure(figsize=(10,6)) plt.semilogx(lrs, history_8.history["loss"]) plt.xlabel("learning rate") plt.ylabel("loss")
Text(0, 0.5, 'loss')

Trong trường hợp này, có thể thấy learning rate tốt nhất khi loss thấp nhất là 0.02 ($2*10^{-2}$).
Bây giờ chúng ta sẽ thử xây dựng mô hình khác với learning_rate là 0.02
model_9 ( xây dựng mô hình với learning rate tốt nhất)
tf.random.set_seed(42) model_9 = Sequential() model_9.add(Dense(5,activation="relu")) model_9.add(Dense(5,activation="relu")) model_9.add(Dense(1,activation="sigmoid")) model_9.compile( loss="binary_crossentropy", optimizer=tf.keras.optimizers.Adam(learning_rate=0.02), metrics=["accuracy"] ) history_9 = model_9.fit( X_train, y_train, epochs=20, verbose=0 )
pd.DataFrame(history_9.history).plot()

So sánh giữa model_7 và model_9
fig, (ax1, ax2) = plt.subplots(nrows=1, ncols=2, figsize=(16,6)) pd.DataFrame(history_7.history).plot(ax=ax1) ax1.set_title("history 7") pd.DataFrame(history_9.history).plot(ax=ax2) ax2.set_title("history 9")
Text(0.5, 1.0, 'history 9')

Có thể thấy với learning rate cao ở model_9 cao hơn model_7 thì model_9 đạt độ chính xác cao hơn dù với epoch ít hơn.
Dự đoán giá trị với model_9 :
plt.figure(figsize=(16,6)) plt.subplot(121);plot_decision_boundary(model_9,X_train, y_train);plt.title("Train") plt.subplot(122);plot_decision_boundary(model_9,X_test, y_test);plt.title("Test")
Đang làm việc với mô hình phân loại 2 lớp Đang làm việc với mô hình phân loại 2 lớp
Text(0.5, 1.0, 'Test')
Như đã thấy, mô hình hoạt động gần như là hoàn hảo
Đây là những loại thử nghiệm bạn sẽ chạy thường xuyên phải làm khi xây dựng mô hình nào đó.
Bắt đầu với các giá trị mặc định và xem chúng hoạt động như thế nào trên dữ liệu của bạn. Nếu chúng làm chưa tốt, hãy tiến hành cải thiện mô hình bằng các phương pháp ở trên.
Phương pháp đánh giá mô hình phân loại
Bên cạnh việc quan sát trực quan mô hình phân tích dữ liệu bằng biểu đồ, chúng ta còn có thể thiết lập đánh giá tổng quan cho mô hình bằng các phương pháp toán học khác trong mô hình phân loại
| Phương pháp đánh giá | Định nghĩa | Code | |||
|---|---|---|---|---|---|
| Accuracy | Số mẫu chính xác trong tổng số mẫu được dự đoán. VD : có 95 mẫu chính xác trong số 100 mẫu thì độ chính xác là 95% | sklearn.metrics.accuracy_score() or tf.keras.metrics.Accuracy() | |||
| Precision | Tỉ lệ true positives trong tổng số mẫu. Precision càng cao thì tỉ lệ dương sai càng thấp ( mô hình dự đoán 1 nhưng thực tế là 0) | sklearn.metrics.precision_score() or tf.keras.metrics.Precision() | |||
| Recall | Tỉ lệ dương đúng trong tổng số mẫu từ true positives và false negatives (mô hình dự đoán 0 nhưng giá trị thực tế là 1 ) | sklearn.metrics.recall_score() or tf.keras.metrics.Recall() | |||
| F1-score | Là sự kết hợp giữa precision và recall thành một không gian đo. 1 là tốt nhất, 0 là tệ nhất | sklearn.metrics.f1_score() | |||
| Confusion matrix | So sánh giá trị dự đoán với giá trị thực, tỉ lệ càng cao thì độ chính xác càng cao. Tất cả các giá trị sẽ tạo thành ma trận thể hiện sự tương quan với nhau | sklearn.metrics.f1_score() sklearn.metrics.plot_confusion_matrix() | |||
| Classification report | Tập hợp các phương pháp đo lường như precision, recall, f1-score | sklearn.metrics.classification_report() |
🔑 Lưu ý: Mỗi phương pháp đánh giá có ý nghĩa riêng tùy thuộc vào từng mô hình phân loại nhất định. Do đó, không có phương pháp nào là tuyệt đối cả.

from sklearn.metrics import confusion_matrix
y_preds_probs = model_9.predict(X_test) y_preds_probs[:5]
array([[5.0821018e-11], [9.9999750e-01], [4.0624646e-09], [1.4701933e-02], [5.4219961e-03]], dtype=float32)
y_pred_labels = np.round(y_preds_probs) y_pred_labels[:5]
array([[0.], [1.], [0.], [0.], [0.]], dtype=float32)
confusion_matrix(y_test, y_pred_labels)
array([[472, 3], [ 0, 525]])
Từ ma trận trên có thể thấy các con số đều nằm trên trục đường chéo, nhưng ma trận trên chỉ biểu diễn những con số, nó không thể hiện rõ ý nghĩa cho người đọc nên chúng ta sẽ vẽ biểu đồ thể hiện sự trực quan cho những số liệu này.
import itertools def plot_confusion_matrix(y_true, y_preds, class_names=None) : cm = confusion_matrix(y_true,y_preds) cm_norm = cm / np.sum(cm, axis=0).astype(np.float32) n_classes = cm.shape[0] fig,ax = plt.subplots(figsize=(12,7)) cax = ax.matshow(cm, cmap=plt.cm.Blues) fig.colorbar(cax) if class_names : labels = class_names else : labels = np.arange(cm.shape[0]) ax.set(title="Confusion matrix", xlabel="Predict label", ylabel="True label", xticks=np.arange(n_classes), yticks=np.arange(n_classes), xticklabels=labels, yticklabels=labels) ax.xaxis.set_label_position("bottom") ax.xaxis.set_ticks_position("bottom") ax.title.set_size(24) threshold =( np.max(cm) + np.min(cm) )/ 2 for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])): plt.text(j,i,f"{cm[i,j]} ({cm_norm[i,j]*100:.2f})%", horizontalalignment="center", color="black" if threshold > cm[i,j] else "white") plot_confusion_matrix(y_test, y_pred_labels)

Đó là những gì cơ bản của mô hình 2 lớp binary class. Hẹn gặp lại các bạn trong phần multi-class classification