Deep Learning với Tensorflow Module 5 phần 1.1: Convolutional Neural Network với dữ liệu 2 class
Để có thể xem chi tiết toàn bộ quá trình thực hiện của phần này, bạn nên xem trên notebook |https://github.com/mthang1801/deep-learning/blob/main/docs/03_1_convolutional_neural_network_binary_class.ipynb
Ở những module trước, chúng ta đã khái quát những vấn đề cơ bản của Tensorflow và tự tay xây dựng mô hình để xử lý những vấn đề khác nhau. Trong module này, chúng ta sẽ đi vào những vấn đề cụ thể và xem cách thức hoạt động của một loại neural network đặc biệt trong deep learning, nó được sử dụng rất phổ biến trong thị giác máy tính (computer vision) đó là convolutional neural networks (CNNs)
🔑 Lưu ý : Trong deep learning, có rất nhiều loại kiến trúc mô hình khác nhau được sử dụng để giải quyết cho những vấn đề cụ thể. Chẳng hạn như sử dụng Convolution neural network để dự đoán dữ liệu hình ảnh, hoặc dữ liệu dưới dạng văn bản. Tuy nhiên, trong thực tế không phải lúc nào những kiến trúc được sử dụng phổ biến là tốt nhất, mà còn có những cái khác còn có thể tốt hơn.
Trong bài viết này, chúng ta sẽ xây dựng và sử dụng mô hình với kiến trúc CNNs để dự đoán dữ liệu hình ảnh.
Nội dung :
- Chuẩn bị tập dữ liệu
- Kiểm tra và đọc dữ liệu
- Kiến trúc của Convolutional Neural Network
- Ví dụ
- model_1 Sử dụng Conv2D layer
- model_2 Sử dụng Dense layer
- Những bước để xây dựng mô hình phân loại 2 class với CNNs
- 4.1 Khám phá, tìm hiểu cấu trúc của tập dữ liệu
- 4.2 Chuẩn bị dữ liệu cho mô hình
- 4.3 Tạo mô hình CNN (bắt đầu với mô hình đơn giản làm cơ sở)
- 4.4 Fitting mô hình (mô hình tìm kiếm các đặc trưng trong dữ liệu
weights,bias) - 4.5 Đánh giá mô hình
- 4.6 Cải thiện mô hình
- 4.7 Mô hình dự đoán
1. Chuẩn bị tập dữ liệu
Tập dữ gồm 2 class (pho, fried_rice) được giải nén từ từ quá trình xử lý từ Food-101 dataset, một tập hợp gồm 101 loại thức ăn khác nhau với 1000 hình ảnh cho mỗi loại được chụp từ thực tế, và quá trình phân tách dữ liệu này được thực hiện ở module 4: preprocessing data.
Do CNNs xử lý rất tốt với các dữ liệu là hình ảnh, do đó, để bắt đầu khám phá về kiến trúc này, chúng ta sẽ làm với các file hình ảnh.
!wget https://www.dropbox.com/s/wlt8lwem9onvnjz/pho_fried_rice.zip
--2021-09-07 01:17:30-- https://www.dropbox.com/s/wlt8lwem9onvnjz/pho_fried_rice.zip Resolving www.dropbox.com (www.dropbox.com)... 162.125.81.18, 2620:100:6035:18::a27d:5512 ... Reusing existing connection to uc6e04d5b6f58ee9f607b29d0a0d.dl.dropboxusercontent.com:443. HTTP request sent, awaiting response... 200 OK Length: 104403862 (100M) [application/zip] Saving to: ‘pho_fried_rice.zip’
pho_fried_rice.zip 100%[===================>] 99.57M 11.6MB/s in 9.5s
2021-09-07 01:17:42 (10.5 MB/s) - ‘pho_fried_rice.zip’ saved [104403862/104403862]# Giải nén tar.gz import zipfile import os def unzip_file(pathname) : if os.path.isdir(pathname) : print("Directory has been existing") return else : zipref = zipfile.ZipFile(pathname) zipref.extractall() print("Unziped file") return zipref.close()
unzip_file("pho_fried_rice.zip")
Unziped file
Kiểm tra và đọc dữ liệu
Một bước rất quan trọng trong bất kỳ dự án machine learning nào đó là đọc và hiểu được dữ liệu, cấu trúc và ý nghĩa của nó. Với dữ liệu hình ảnh, một loại dữ liệu không có cấu trúc, việc quan sát bằng cách hiển thị cũng là phương pháp trực quan sử dụng phổ biến.
Cấu trúc file được tải xuống và giải nén cụ thể như sau :
- Một thư mục
trainchứa 2 folderphovàfried_rice, mỗi folder chứa 750 hình ảnh liên quan về nó dùng để train dữ liệu - Tương tự thư mục
testcũng chứa 2 folder trên, nhưng chúng chỉ chứa 250 hình ảnh để sau khi mô hình train xong có thể tiến hành dự đoán
Ví dụ :
pho_fried_rice <- top level folder
└───train <- training images
│ └───pho
│ │ │ 1005681.jpg
│ │ │ 10011443.jpg
│ │ │ ...
│ └───fried_rice
│ │ 1004221.jpg
│ │ 1008935.jpg
│ │ ...
│
└───test <- testing images
│ └───pho
│ │ │ 1002382.jpg
│ │ │ 10020153.jpg
│ │ │ ...
│ └───fried_rice
│ │ 10023430.jpg
│ │ 1028159.jpg
│ │ ...Tạo hàm kiểm tra xem có bao nhiêu hình ảnh trong mỗi folder tính từ root folder (Folder gốc)
import os def walk_through_directory(dirname) : for dirpath, dir_names, file_names in os.walk(dirname) : print(f"Có {len(dir_names)} folders và {len(file_names)} files trong thư muc {dirpath}")
walk_through_directory("pho_fried_rice")
Có 2 folders và 0 files trong thư muc pho_fried_rice Có 2 folders và 0 files trong thư muc pho_fried_rice/train Có 0 folders và 750 files trong thư muc pho_fried_rice/train/pho Có 0 folders và 750 files trong thư muc pho_fried_rice/train/fried_rice Có 2 folders và 0 files trong thư muc pho_fried_rice/test Có 0 folders và 250 files trong thư muc pho_fried_rice/test/pho Có 0 folders và 250 files trong thư muc pho_fried_rice/test/fried_rice
Kiểm tra trong thư mục pho_fried_rice/train/pho xem có những file cụ thể nào :
print(os.listdir("pho_fried_rice/train/pho"))
['1289035.jpg', '1940783.jpg', '4937.jpg', '632134.jpg', '25586.jpg', '1865868.jpg', '813319.jpg', '3125468.jpg', .... '2128884.jpg', '915686.jpg', '2832528.jpg', '267779.jpg', '2682970.jpg', '3268356.jpg', '2574372.jpg', '1738472.jpg']
Nếu bạn không muốn sử dụng thư viện os trong python, bạn có thể sử dung lệnh !ls của terminal
!ls pho_fried_rice/train/pho
1005681.jpg 154603.jpg 2338556.jpg 2948309.jpg 3557139.jpg 543660.jpg ... 1521706.jpg 232553.jpg 2942387.jpg 3534971.jpg 53997.jpg 998863.jpg 1531874.jpg 233064.jpg 2948263.jpg 3538985.jpg 542087.jpg 999247.jpg
Như vậy, chúng ta đã thấy được tổng quan cấu trúc của dữ liệu. Tiếp theo, như đã thấy trong mỗi folder train, test đều có folder nhỏ hơn, những folder đó gắn liền với tên của nó thì đại diện cho 1 class. Do đó, để biết được tên của các class, chúng ta sẽ lấy tên của mỗi folder nhỏ đó và sắp xếp chúng theo thứ tự
import pathlib import numpy as np data_dir = pathlib.Path("pho_fried_rice/train") class_names = np.array(sorted([item.name for item in data_dir.glob("*")])) class_names
array(['fried_rice', 'pho'], dtype='<U10')
Từ những khám phá trên, có thể kết luận folder pho_fried_rice gồm có 2 tập dữ liệu train và test tương ứng với 750 và 250 file ảnh cho mỗi class.
Tiếp theo,ta sẽ hiển thị hình ảnh ngẫu nhiên của một class trong tập train hoặc test. Để làm được điều này, ta sẽ tạo một hàm có tên plot_random_image nhận 3 tham số :
+ target_dir : đường dẫn liên kết đến tập train hoặc test
+ target_class : tên class để hiển thị ảnh ngẫu nhiên
+ n_samples : Số lượng hình ảnh muốn hiển thị
import random import math import matplotlib.pyplot as plt
def plot_random_images(target_dir, target_class, n_samples=1) : path_dir = os.path.join(target_dir,target_class) list_random_image_names = random.sample(os.listdir(path_dir), k=n_samples) n_cols = 3 n_rows = math.ceil(n_samples / n_cols) plt.figure(figsize=(n_cols*4, n_rows*4 )) images = [] for i, image_name in enumerate(list_random_image_names) : image_path = os.path.join(path_dir, image_name) image = plt.imread(image_path) images.append(image) plt.subplot(n_rows,n_cols,i+1) plt.imshow(image) plt.axis(False) plt.suptitle(f"Images for : {target_class}",horizontalalignment="center") return images
pho_images = plot_random_images("pho_fried_rice/train", "pho", 5)
fried_rice_images = plot_random_images("pho_fried_rice/train", "fried_rice", 4)
Trên đây là những hình ảnh được vẽ từ ma trận của chúng, vậy phía sau những hình ảnh này thì hình thù của chúng như thế nào ?
VD: ta lấy hình đầu tiên của danh sách các hình ảnh từ list pho_images, khi in ra nó sẽ là một ma trận
pho_image_item = pho_images[0] pho_image_item
array([[[ 61, 31, 33], [ 51, 25, 26], [ 46, 26, 27], ...,
[[ 85, 37, 49],
[ 86, 36, 48],
[ 86, 34, 47],
...,
[ 43, 10, 17],
[ 47, 14, 21],
[ 51, 18, 25]]], dtype=uint8)Hình thù cụ thể của hình :
pho_image_item.shape
(512, 288, 3)
hình thái của hình ảnh trên (384,512,3) đại diện trưng cho (Chiều rộng (Width), Chiều cao(Height), Kênh màu(Color channels)). Như vậy, hình ảnh trên có chiều rộng là 384, chiều cao là 512, và sô kênh màu là 3 RGB(red,green blue)
Trong trường hợp của tập dữ liệu này, chiều rộng và chiều cao có thể thay đổi kích thước, nhưng kênh màu luôn luôn là 3.
Một điều lưu ý, tất cả các phần tử trong ma trận đều nằm trong khoảng từ 0-255. Điều này là vì phạm vi màu RGB đều chỉ nằm trong khoảng này. Ví dụ red=255,green=0,blue=0 thì sẽ là màu đỏ...
Chính vì có sự khác thay đổi trong phạm vi màu đó nên khi xây dựng mô hình, nó sẽ tìm kiếm những điểm khác biệt giữa pho và fried_rice. Từ đó, nó sẽ tìm kiếm các điểm đặc trưng (weights và bias) trong mỗi giá trị pixel khác nhau để xác định hình ảnh đó thuộc class nào
🔑 Lưu ý : Như đã đề cập ở những module trước, có rất nhiều mô hình machine learning (bao gồm cả neural network) chúng hoạt động tốt trên những giá trị được chuẩn hóa từ 0-1. Do đó, một trong những bước quan trọng nhất trước khi tiến hành xây dựng mô hình là phải scale (chuẩn hóa) dữ liệu. Ví giá trị lớn nhất của hình ảnh luôn cố định là 255, nên muốn scale dữ liệu này, chỉ cần lấy tất cả phần từ chia cho 255.
pho_image_item / 255.
array([[[0.23921569, 0.12156863, 0.12941176],
[0.2 , 0.09803922, 0.10196078],
[0.18039216, 0.10196078, 0.10588235],
...,
[0.16862745, 0.03921569, 0.06666667],
[0.18431373, 0.05490196, 0.08235294],
[0.2 , 0.07058824, 0.09803922]]])
2. Kiến trúc của Convolutional Neural Network
Convolutional neural networks không có sự khác biệt giữa các loại khác nhau của nó trong deep learning neural network. Thực ra, chúng được tạo bằng nhiều cách khác nhau. Dưới đây là các thành phần xây dựng nên Convolutional neurals network :
| Hyperparameter - Layer type | Chức năng | Các tham số cụ thể | |||
|---|---|---|---|---|---|
| Input images (Dữ liệu hình ảnh được đưa vào mô hình) | Hình ảnh được đưa vào để tìm các đặc trưng trong nó | Bất kỳ hình ảnh nào được chụp hoặc lấy từ video | |||
| Input layer | Tiếp nhận các hình ảnh và xử lý chúng trước khi chuyển tiếp đến các layer khác | input_shape = [batch_size, image_height, image_width, color_channels] | |||
| Convolution layer (layer tích chập) | Layer này có nhiệm vụ phân tách, tìm kiếm và học và tổng hợp các đặc tính quan trọng nhất của một hình ảnh truyền vào | tf.keras.layers.ConvXD | |||
| Hidden activation | Hàm để giúp các đặc tính được học trở nên phi tuyến (không tuyến tính hay theo quán tính của một đường thằng) | Thường sử dụng (tf.keras.activations.relu) | |||
| Pooling layer | Giảm kích thước của các đặc tính hình ảnh được học | Average (tf.keras.layers.AvgPool2D) hoặc Max (tf.keras.layers.MaxPool2D) | |||
| Full connected layer | Tinh chỉnh thêm các đặc tính đã được học từ các layer tích chập (convolution layer) | tf.keras.layers.Dense | |||
| Output layer | Từ các đặc tính đã được học để tạo ra kết quả là xác xuất cho mỗi class trong tổng số các class đó | output_shape = [number_of_classes] (e.g. 4 for pho, fried_rice, pizza, hoặc steak) | |||
| Output activation | Thêm hàm phi tuyến cho layer output | tf.keras.activations.sigmoid cho mô hình 2 class (binary classification) hoặc tf.keras.activations.softmax cho mô hình nhiều hơn 2 class |
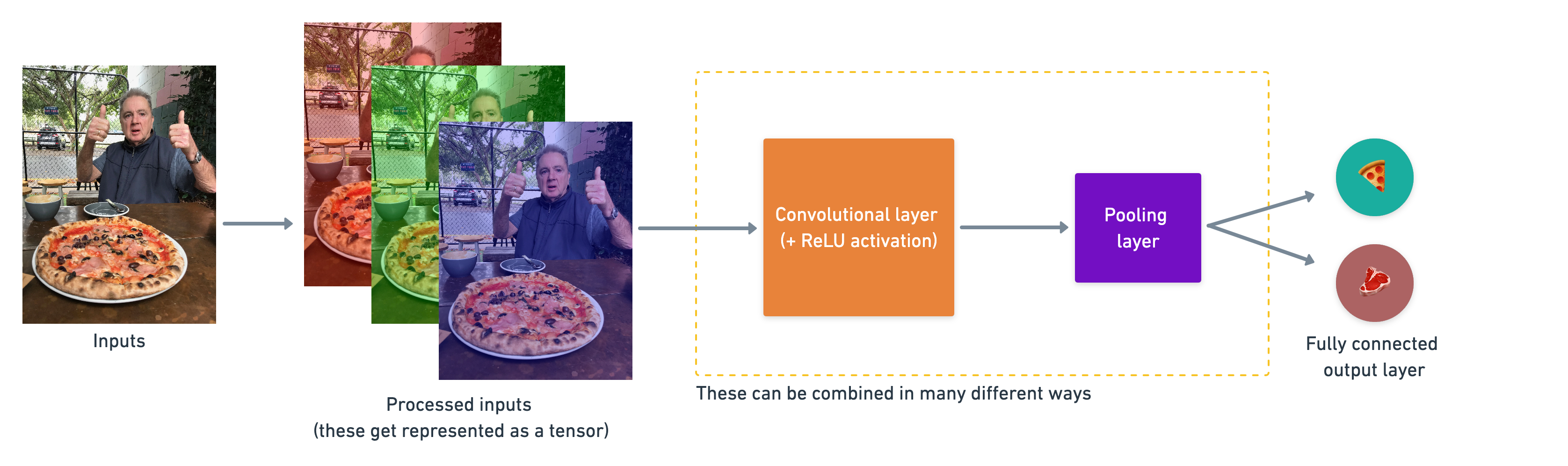
Ví dụ
Ở phần trên, chúng ta đã kiểm tra mỗi class trong 2 tập dữ liệu train và test. Với tập dữ liệu train, mỗi class đều có 750 file hình, còn với tập dữ liệu test, mỗi clas đều có 250 file hình, và tất cả những hình này không phải lúc nào chúng cũng có cùng kích thước với nhau.
Nếu sử dụng machine learning để đánh giá mô hình theo như original dataset authors paper, we see they used a Random Forest machine learning model, có thể thấy rằng độ chính xác trung bình của mô hình dự đoán chỉ khoảng ~50%. Vậy chúng ta sẽ xem 50% độ chính xác là cơ sở để xây dựng cho những mô hình dự đoán tiếp theo phải tốt hơn mô hình này.
Đoạn code dưới đây sẽ liên kết từ đầu đến cuối cho quá trình xây dựng mô hình cho đến đánh giá và dự đoán mô hình bằng Convolutional Neural network (CNN). Do đó, sẽ có nhiều đoạn code mà bạn chưa từng gặp trước đó, nhưng đừng lo lắng, ở những phần sau sẽ làm rõ từng khái niệm và ý nghĩa của chúng.
Tuy nhiên, trước khi đọc những đoạn code dưới đây, bạn nên giành một giờ để đọc phần giải thích về cách thức hoạt động của CNN tại CNN explainer webpage.
🔑 Lưu ý: Quá trình xử lý dữ liệu bằng hình ảnh hoặc những dữ liệu ma trận phức tạp nếu bạn xử lý bằng CPU sẽ diễn ra rất chậm. Do đó, trong Tensorflow có hỗ trợ xử lý những kiểu dữ liệu phức tạp này bằng GPU với tốc độ nhanh hơn CPU >30 lần. Tuy nhiên, để có thể mua một GPU phục vụ cho quá trình học tập sẽ rất tốn kém, nhưng may mắn thay https://colab.research.google.com/ có hỗ trợ miễn phí chạy mô hình với GPU. Trước khi tiến hành chạy tất cả, trên thanh công cụ bạn chọn
Thời gian chạy (Runtime) -> Thay đổi thời gian chạy(Change Runtime Type) -> Chọn GPU thay vì None. Sau đó tiến hànhChạy tất cả (Run all).
Để kiểm tra xem notebook hiện tại đã chạy bằng GPU chưa bạn có thể gõ lệnh sau :
!nvidia-smi -L
model_1 Sử dụng Conv2D layer
import tensorflow as tf from tensorflow.keras.preprocessing.image import ImageDataGenerator from tensorflow.keras import Sequential, layers
tf.random.set_seed(42) train_datagen = ImageDataGenerator(rescale=1/255.) test_datagen = ImageDataGenerator(rescale=1/255.) train_dir = "pho_fried_rice/train" test_dir = "pho_fried_rice/test" train_dataset = train_datagen.flow_from_directory(train_dir, target_size=(224,224), # đồng bộ kích thước hình ảnh (228,288) class_mode="binary",# 2 class nên là binary, nếu nhiều class là categorical, batch_size=32, #batch size có chức năng chia tập dữ liệu khổng lồ thành các cụm nhỏ hơn để xử lý, seed=42) test_dataset = test_datagen.flow_from_directory(test_dir, target_size=(224,224), class_mode="binary", batch_size=32, seed=42) model_1 = Sequential([ layers.Conv2D(filters=10,kernel_size=3, strides=1, padding="valid",activation="relu", input_shape=(224,224,3)), layers.Conv2D(10,3, activation="relu"), layers.MaxPool2D(), layers.Conv2D(10,3,activation="relu"), layers.Conv2D(10,3,activation="relu"), layers.MaxPool2D(), layers.Flatten(), layers.Dense(1, activation="sigmoid") ]) model_1.compile( loss="binary_crossentropy", optimizer="adam", metrics=["accuracy"] ) model_1_history = model_1.fit( train_dataset, steps_per_epoch=len(train_dataset), epochs=5, validation_data=test_dataset, validation_steps=len(test_dataset) )
Found 1500 images belonging to 2 classes.
Found 500 images belonging to 2 classes.
Epoch 1/5
47/47 [==============================] - 41s 246ms/step - loss: 0.6638 - accuracy: 0.6060 - val_loss: 0.5676 - val_accuracy: 0.7620
...
Epoch 5/5
47/47 [==============================] - 10s 219ms/step - loss: 0.3386 - accuracy: 0.8580 - val_loss: 0.3931 - val_accuracy: 0.8140Sau 5 epochs, model_1 đã đạt val_accuracy ~ 83%, độ chính xác vượt trội so với mô hình cơ sở ~50%. Tuy nhiên, mô hình mà chúng ta đang thực hiện mới chỉ dự đoán 2 class so với tổng số 101 class trong tập dữ liệu. Vì vậy không thể so sánh trực tiếp với mô hình cơ sở lúc này.
Sau khi fit mô hình, kiểm tra xem kiến trúc mô hình :
model_1.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 222, 222, 10) 280
_________________________________________________________________
conv2d_1 (Conv2D) (None, 220, 220, 10) 910
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 110, 110, 10) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 108, 108, 10) 910
_________________________________________________________________
conv2d_3 (Conv2D) (None, 106, 106, 10) 910
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 53, 53, 10) 0
_________________________________________________________________
flatten (Flatten) (None, 28090) 0
_________________________________________________________________
dense (Dense) (None, 1) 28091
=================================================================
Total params: 31,101
Trainable params: 31,101
Non-trainable params: 0
_________________________________________________________________Tên các layers của model_1 đã được giải thích trong CNN explainer website, bạn có thể tham khảo từ đó.
Có một số thứ ở mô hình trên bạn chưa từng thấy, bây giờ sẽ cắt nghĩa một chút :
- Đầu tiên là class
ImageDataGeneratorvới tham sốrescale:
model_2 sử dụng Dense layer
Để dẫn chứng cho cách Neural network điều chỉnh phù hợp với nhiều vấn đề khác nhau, chúng ta sẽ quay lại mô hình đã được build của model_3 sử dụng với Dense layer.
Nếu chúng ta sử dụng các layer, unit như trước ngoài trừ :
- data : Hiện tại dữ liệu là những hình ảnh thay vì các điểm.
- Hình dạng của dữ liệu nhập vào : Chúng ta phải cho neural network biết hình dạng của hình ảnh mà chúng ta đang làm việc. Với Dense layer, một thực tế phổ biến là phải reshape tất cả hình ảnh cùng một kích thước. Chúng ta có hình ảnh kích thước (224,224,3) , nghĩa là chiều rộng là 224, chiều cao là 224, và độ sâu là 3 cho các kênh màu red, green, blue.
tf.random.set_seed(42) model_2 = Sequential([ layers.Flatten(input_shape=(224,224,3)), layers.Dense(10, activation="relu"), layers.Dense(10, activation="relu"), layers.Dense(1, activation="sigmoid"), ]) model_2.compile( loss="binary_crossentropy", optimizer="adam", metrics=["accuracy"] ) model_2_history = model_2.fit( train_dataset, steps_per_epoch=len(train_dataset), epochs=5 , validation_data=test_dataset, validation_steps=len(test_dataset) )
Epoch 1/5
47/47 [==============================] - 10s 201ms/step - loss: 0.9584 - accuracy: 0.4933 - val_loss: 0.6932 - val_accuracy: 0.5000
...
Epoch 5/5
47/47 [==============================] - 9s 195ms/step - loss: 0.6932 - accuracy: 0.5000 - val_loss: 0.6932 - val_accuracy: 0.5000Mô hình không thay đổi val_accuracy sau 5 epochs với độ chính xác 50%, có thể thấy một điều rằng nó không học được bất kỳ điều gì.
Kiến trúc của mô hình model_2:
model_2.summary()
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten_1 (Flatten) (None, 150528) 0
_________________________________________________________________
dense_1 (Dense) (None, 10) 1505290
_________________________________________________________________
dense_2 (Dense) (None, 10) 110
_________________________________________________________________
dense_3 (Dense) (None, 1) 11
=================================================================
Total params: 1,505,411
Trainable params: 1,505,411
Non-trainable params: 0model_1 có total_params chỉ với 31,101 những học được rất nhiều (val_accuracy ~83%) trong khi model_2 có total_params lên đến 1,505,411 những không học được bất cứ thứ gì (val_accuracy ~50%).
🔑 Lưu ý : Có thể bạn nghĩ rằng
Trainable paramslà những đặc trưng mà mô hình học được từ dữ liệu. Về logic, con số này càng lớn thì mô hình càng tốt. Trong nhiều trường hợp, điều đó là đúng. Nhưng với trường hợp củamodel_1vàmodel_2, điểm khác biệt ở đây là 2 kiểu mô hình khác nhau. Với loạt chuỗi dense layer củamodel_2do có nhiều learnable parameters khác nhau được kết nối chéo với nhau nên dẫn đến số lượng learnable parameters rất cao. Trong khi với convolutional neural network chỉ tìm cách sắp xếp và học những đặc tính nào của hình ảnh là quan trọng. Chính vì vậy, mặc dù convolutional neural network có ít learnable parameter hơn nhưng chúng thường phân tách tốt hơn các đặc tính khác nhau trong một hình ảnh.
Vì model_2 không học được gì, liệu tăng số lượng Dense layer cùng với neuron trong mỗi layer và train lâu hơn thì model_2 có cải thiện được không nhỉ ? 🤔
tf.random.set_seed(42) model_3 = Sequential([ layers.Flatten(input_shape=(224,224,3)), layers.Dense(128,activation="relu") , layers.Dense(128,activation="relu") , layers.Dense(128,activation="relu") , layers.Dense(1,activation="sigmoid") , ]) model_3.compile( loss="binary_crossentropy", optimizer="adam", metrics=["accuracy"] ) model_3.fit( train_dataset, steps_per_epoch=len(train_dataset), epochs=10, validation_data=test_dataset, validation_steps=len(test_dataset) )
Epoch 1/10
47/47 [==============================] - 10s 204ms/step - loss: 6.2395 - accuracy: 0.5053 - val_loss: 5.2971 - val_accuracy: 0.5020
...
Epoch 10/10
47/47 [==============================] - 9s 199ms/step - loss: 0.5242 - accuracy: 0.7360 - val_loss: 0.5705 - val_accuracy: 0.7180
<keras.callbacks.History at 0x7f8000013490>model_3.summary()
Model: "sequential_2"
...
Total params: 19,300,865
Trainable params: 19,300,865
Non-trainable params: 0model_3 mô hình đã học nhưng trainable parameters tăng lên rất nhiều so với model_2 nhưng xét về độ chính xác của mô hình vẫn không qua được model_1.