Deep Learning với Tensorflow Module 7 phần 1: Dự án phân loại 101 loai thức ăn
Bài viết này là phần tóm tắt quá trình thực hiện của dự án. Để xem toàn bộ quá trình thực hiện một cách chi tiết bạn có thể đọc tại notebook project 1 101 classes food
Ở bài viết trước module 6 : part 3, chúng ta đã xây dựng mô hình transfer learning với 10% dữ liệu cho tất cả các class. Qua kết quả đánh giá mô hình, có thể thấy rằng nó đã vượt qua mô hình cơ sở từ Food101 paper với chỉ 10% dữ liệu được train.
Nhưng bạn có tự hỏi sẽ như thế nào nếu chúng ta sử dụng tất cả dữ liệu đem vào mô hình? Và điều đó sẽ thực hiện trong dự án này. Chúng ta sẽ xây dựng mô hình Food Vision với đầy đủ tập dữ liệu từ 101 Food (có khoảng 75750 hình ảnh train, và 25250 hình ảnh test).
Lần này, chúng ta có mục tiêu sẽ đánh bại DeepFood, một bài báo năm 2016 sử dụng neural network được train trong 2-3 ngày để đạt được độ chính xác top 1 là 77,4%.
| 🍔👁 Food Vision Big™ | 🍔👁 Food Vision mini | ||||
|---|---|---|---|---|---|
| Dataset source | TensorFlow Datasets | Preprocessed download from Kaggle | |||
| Train data | 75,750 images | 7,575 images | |||
| Test data | 25,250 images | 25,250 images | |||
| Mixed precision | Yes | No | |||
| Data loading | Performanant tf.data API | TensorFlow pre-built function | |||
| Target results | 77.4% top-1 accuracy (beat DeepFood paper) | 50.76% top-1 accuracy (beat Food101 paper) |
Cùng với việc cố gắng đánh bại bài báo DeepFood, chúng ta sẽ tìm hiểu về hai phương pháp để cải thiện đáng kể tốc độ train cho mô hình : + Prefetching + Mixed precision training
Nội dung bài viết này gồm : 1. Sử dụng Bộ dữ liệu TensorFlow để tải xuống 2. Khám phá dữ liệu 3. Tạo hàm tiền xử lý dữ liệu 4. Phân cụm & chuẩn bị tập dữ liệu để lập mô hình (làm cho tập dữ liệu của chúng ta được load nhanh) 5. Tạo callback function của mô hình trước khi bắt đầu xây dựng nó. 6. Thiết lập train độ chính xác hỗn hợp (mixed precision training) 7. Xây dựng mô hình trích xuất đặc trưng 8. Tinh chỉnh mô hình trích xuất đặc trưng 9. Đánh giá mô hình, dự đoán phân tích các yếu tố trong mô hình từ dữ liệu test. 10. Dự đoán hình ảnh ngẫu nhiên ngoài dữ liệu test
Với bài viết này, chúng ta cần sử dụng GPU, nhưng có một chút khác biệt. Vì chúng ta sẽ sử dụng kỹ thuật train độ chính xác hỗn hợp (mixed precision training) nên bạn cần tiếp cận với những GPU có điểm tương thích trên 7.0.
Google Colab cung cấp cho chúng ta một số GPU có sẵn gồm K80, P100, T4. Tuy nhiên, chỉ có T4 là tương thích với mixed precision training được đánh giá trên 7.0. Do đó, trước khi tiếp tục chúng ta cần đảm bảo rằng chúng ta đã truy cập vào GPU Tesla T4, nếu không bạn vẫn có thể áp dụng như bình thường nhưng nó sẽ không thể tăng tốc cho mô hình train.
🔑 mixed precision training : là sự kết hợp giữa kiểu dữ liệu float32 (single precision) và float16 (half-precision) để tăng tốc mô hình train (tăng gấp 3 lần trên GPU hiện đại).
Kiểm tra GPU hiện tại trên google colab.
!nvidia-smi -L
GPU 0: Tesla K80 (UUID: GPU-0c6e9667-4e70-965a-6f3f-1cf822c3d8f2)
Vì kỹ thuật độ chính xác hỗn hợp đã được giới thiệu trong TensorFlow 2.4.0, hãy đảm bảo rằng bạn đã có ít nhất TensorFlow 2.4.0+.
import tensorflow as tf
tf.__version__
Tải utility_functions
!wget https://www.dropbox.com/s/v4sla7jvi9cltg8/utility_functions.py
from utility_functions import compare_history,create_tensorboard_callback,plot_confusion_matrix,plot_loss_curves,unzip_file,walk_through_directory
1. Sử dụng bộ dữ liệu TensorFlow để tải dữ liệu xuống
Ở những bài trước, chúng ta đã tải xuống hình ảnh đồ ăn của mình (từ bộ dữ liệu Food101) từ cloud storage. Và đây là quy trình làm việc điển hình bạn sẽ sử dụng nếu bạn đang làm việc trên tập dữ liệu của riêng mình. Tuy nhiên, có một cách khác để chuẩn bị sẵn bộ dữ liệu để sử dụng với TensorFlow. Đối với nhiều bộ dữ liệu phổ biến nhất trong thế giới học máy (thường được gọi và sử dụng làm điểm chuẩn). Bạn có thể truy cập chúng thông qua Bộ dữ liệu TensorFlow Datasets (TFDS).
TensorFlow Datasets là một nơi dành cho các bộ dữ liệu học máy đã được chuẩn bị và sẵn sàng để sử dụng.
Tại sao sử dụng Bộ dữ liệu TensorFlow? + Tải xuống dữ liệu có sẵn trong Tensors + Thực hành trên các bộ dữ liệu được thiết lập tốt + Thử nghiệm với các kỹ thuật tải dữ liệu khác nhau (giống như chúng ta sẽ sử dụng trong notebook này) + Thử nghiệm nhanh các tính năng TensorFlow mới (chẳng hạn như train độ chính xác hỗn hợp).
Tại sao không sử dụng Bộ dữ liệu TensorFlow? + Các tập dữ liệu là tĩnh (chúng không thay đổi, giống như các tập dữ liệu trong thế giới thực) + Có thể không phù hợp với vấn đề cụ thể (nhưng vẫn rất đáng để thử nghiệm)
Để bắt đầu sử dụng Tập dữ liệu TensorFlow, chúng ta sẽ import tensorflow_datasets
import tensorflow_datasets as tfds
Để tìm tất cả các tập dữ liệu có sẵn trong TensorFlow Datasets, chúng ta có thể sử dụng phương thức list_builders().
print(tfds.list_builders())
['abstract_reasoning', 'accentdb', ..., 'yelp_polarity_reviews', 'yes_no']
Sau đó, chúng ta sẽ kiểm tra xem food101 có thuộc danh sách trong tập dữ liệu trên hay không.
if "food101" in tfds.list_builders() : print("food101 nằm trong tập dữ liệu Tensors") else : print("Không tìm thấy food101")
food101 nằm trong tập dữ liệu Tensors
Để kết nối đến tập dữ liệu Food101 từ TFDS, chúng ta có thể sử dụng phương thức tfds.load().
Trong phương thức này, sẽ có một số tham số như sau :
+ name (str) : Tên tập dữ liệu (VD : food101).
+ split (list, optional) : Tách dữ liệu ra thành các phần khác nhau (VD: ['train', 'validation'])
+ shuffle_files (bool) : Liệu có xáo trộn dữ liệu hay không, mặc định là False.
+ as_supervised (bool) : True để download dữ liệu dươi dạng ((data, label)), hoặc False dưới dạng dictionary.
+ with_info (bool) : True để tải dữ liệu đi kèm với thông tin về dữ liệu đó.
(train_data, test_data), dataset_info = tfds.load("food101", split=["train", "validation"], shuffle_files=True, as_supervised=True, with_info=True)
Bây giờ chúng ta sẽ lấy thông tin từ tập dữ liệu của, bắt đầu với tên các class.
Lấy tên class từ tập dữ liệu TensorFlow Datasets thông qua biến "dataset_info" (bằng cách sử dụng tham số as_supervised = True trong phương thức tfds.load(), lưu ý: điều này sẽ chỉ hoạt động đối với tập dữ liệu được giám sát trong TFDS).
Chúng ta có thể truy cập đến tên class của một tập dữ liệu cụ thể bằng cách sử dụng thuộc tính dataset_info.features và truy cập thuộc tính tên của khóa "label".
dataset_info
dataset_info.features
FeaturesDict({ 'image': Image(shape=(None, None, 3), dtype=tf.uint8), 'label': ClassLabel(shape=(), dtype=tf.int64, num_classes=101), })
class_names = dataset_info.features["label"].names print(class_names[:10])
['apple_pie', 'baby_back_ribs', 'baklava', 'beef_carpaccio', 'beef_tartare', 'beet_salad', 'beignets', 'bibimbap', 'bread_pudding', 'breakfast_burrito']
2. Khám phá dữ liệu
Chúng ta sẽ tìm hiểu chi tiết bên trong tập dữ liệu này: + Hình dạng của dữ liệu input + Kiểu dữ liệu input + Label của input trong như thế nào? Liệu nó đã được one-hot hay là label-encoded (một số đại diện cho tên của label) + Label có khớp với tên class hay không.
Để thực hiện, chúng ta hãy lấy một mẫu đầu tiên ra khỏi dữ liệu train (sử dụng phương thức .take(count)).
for image, label in train_data.take(1): print(f"image shape: {image.shape}") print(f"image dtype: {image.dtype}") print(f"label: {label}") print(f"tên class: {class_names[label]}")
image shape: (384, 512, 3) image dtype: <dtype: 'uint8'> label: 97 tên class: takoyaki
Bởi vì chúng ta đã sử dụng tham số shuffle=True trên tfds.load() nên dữ liệu đã được không theo thứ tự như tập dữ liệu gốc. Chính vì vậy mỗi lần gọi phương thức take() như trên nó sẽ trả về một dữ liệu khác nhau.
Tensor của hình ảnh trong TFDS sẽ như thế nào?
image
<tf.Tensor: shape=(384, 512, 3), dtype=uint8, numpy= array([[[ 54, 30, 26], [ 57, 33, 29], [ 72, 49, 43], ..., [ 4, 4, 4], [ 6, 6, 6], [ 6, 6, 6]]], dtype=uint8)>
Giá trị lớn nhất và nhỏ nhất trong tensor?
tf.reduce_min(image), tf.reduce_max(image)
(<tf.Tensor: shape=(), dtype=uint8, numpy=0>, <tf.Tensor: shape=(), dtype=uint8, numpy=255>)
Có thể thấy bộ dữ liệu hình ảnh có giá trị trong phạm vi từ 0 đến 255, và có kiểu dữ liệu uint8
Hiển thị hình ảnh bất kỳ
Quá trình khám phá dữ liệu không thể thiếu bước biểu diễn dữ liệu dưới dạng đồ thị hoặc hình ảnh. Do đó, chúng ta sẽ hiển thị hình ảnh qua biến image ở trên.
import matplotlib.pyplot as plt
plt.imshow(image) plt.title(f"{class_names[label]}") plt.axis(False)

3. Tạo hàm tiền xử lý dữ liệu
Ở những phần trước, chúng ta sử dụng phương thức tf.keras.preprocessing.image_dataset_from_directory() đưa đường dẫn của folder chứa ảnh đến để nó thực hiện tiền xử lý dữ liệu giúp chúng ta.
Tuy nhiên, bởi vì trong project này, chúng ta thực sự không sử dụng folder tải lên trên notebook mà thay vào đó download tập dữ liệu này từ Tensorflow datasets, cho nên có một số bước tiền xử lý mà chúng ta phải thực hiện trước khi nó sẵn sàng tạo mô hình.
Cụ thể hơn, dữ liệu của chúng ta hiện là:
+ Kiểu dữ liệu uint8
+ Kích thước giữa các hình chưa được đồng bộ
+ Chưa được chuẩn hóa (đưa về 0 -1)
Trái lại, mô hình thường thích dữ liệu :
+ Kiểu float32
+ Tất cả hình ảnh phải có cùng kích thước
+ Dữ liệu được chuẩn hóa
Để thực hiện điều này, chúng ta sẽ tạo hàm preprocessing_image() với các chức năng sau :
+ Resize lại hình ảnh với td.image.resize()
+ Chuyển đổi kiểu dữ liệu về float32 với tf.cast()
🔑 Lưu ý: Trong bài viết này, chúng ta sẽ sử dụng mô hình
EfficientNet, các dữ liệu khi được đưa vào mô hình này sẽ được chuẩn hóa bởi layer có sẵn của nó. Cho nên chúng ta không cần phải thực hiện bước này trongpreprocessing_image(). Tuy nhiên, đối với những mô hình khác không được chuẩn hóa bên trong nó, bạn có thể thêm một bước là lấy tất cả giá trị của hình ảnh đó chia cho 255. hoặc tạo một layer chuẩntf.keras.experimental.preprocessing.Rescaling()
import tensorflow as tf
def preprocessing_image(image, label, image_shape=(224,224)) : """ Parameters : image : an tensor of image label : the label-encoded of image image_shape (default (224,224)) : The size of image following with width, height """ image = tf.image.resize(image, size=image_shape) image = tf.cast(image,dtype=tf.float32) # Vì label trong tập dữ liệu là label-encoded, chúng ta sẽ one-hot để sau này mô hình có thể học và dự đoán xác suất trên từng class return image, label
print(f""" image shape :{image.shape} image dtype : {image.dtype} image : {image} """) preprocessed_img, label = preprocessing_image(image, label) print(f""" image shape :{preprocessed_img.shape} image dtype : {preprocessed_img.dtype} image: {preprocessed_img} """)
image shape :(384, 512, 3) image dtype : <dtype: 'uint8'> image : [[[ 54 30 26] [ 57 33 29] [ 72 49 43] ... [ 4.7091513 4.7091513 4.7091513] [ 4.025515 4.025515 4.025515 ] [ 6. 6. 6. ]]]
Hình ảnh input được chuyển đổi từ uint8 thành float32 và được resize lại từ hình dạng hiện tại của nó thành (224, 224, 3).
# chia cho 255 (cho khả năng dung nạp matplotlib) plt.imshow(preprocessed_img / 255.) plt.title("Hình ảnh đã được xử lý") plt.axis(False)

3. Phân cụm & chuẩn bị tập dữ liệu để lập mô hình (làm cho tập dữ liệu của chúng ta được load nhanh)
Trước khi đưa dữ liệu vào mô hình, chúng ta sẽ phải đưa chúng ta thành các cụm vì không thể nào mô hình trong một thời điểm có thể train được toàn bộ 75720 hình ảnh vì lý do bộ nhớ cũng như hiệu suất xử lý. Do đó, Chúng ta sẽ biến dữ liệu của từ 101.000 hình ảnh gồm cả train và test thành từng cụm với mỗi cụm gồm 32 cặp hình ảnh và label tương ứng với dữ liệu đó. Điều này cho phép mô hình fit được dữ liệu phù hợp trên GPU.
Để làm điều này một cách hiệu quả, chúng ta sẽ tận dụng một số phương pháp từ API tf.data.
📖 Nguồn : Để tải dữ liệu theo cách hiệu quả nhất có thể, xem tài liệu TensorFlow trên Better performance with the tf.data API.
Đặc biệt, chúng ta sẽ sử dụng :
+ map() : ánh xạ một hàm được xác định trước đến một tập dữ liệu đích (VD : ánh xạ preprocessing_image vào tensor hình ảnh).
+ shuffle() : xáo trộn ngẫu nhiên các phần tử của tập dữ liệu mục tiêu với buffer_size (buffer_size là kích thước mẫu bị xáo trộn. Lý tưởng nhất là buffer_size có cùng với kích thước dữ liệu nhưng điều này sẽ chiếm bộ nhớ)
+ batch() : đưa thành phần của tập dữ liệu đích thành từng cụm (kích thước trong mỗi cụm được định nghĩa batch_size, thường là 32)
+ prefetch() : chuẩn bị các cụm dữ liệu tiếp theo trong khi các cụm dữ liệu khác đang được tính toán ( điều này giúp cải thiện tốc độ load dữ liệu nhưng sẽ tốn bộ nhớ ).
+ (Thêm) cache() : lưu các phần tử trong tập dữ liệu đích vào bộ nhớ đệm (lưu dữ liệu để sử dụng sau này), tiết kiệm thời gian load (sẽ chỉ hoạt động nếu tập dữ liệu của đủ nhỏ để phù hợp với bộ nhớ, ram có sẵn trên Colab tiêu chuẩn chỉ có 12GB bộ nhớ)
Những điều cần lưu ý:
- Không thể tạo hàng loạt các cụm chứa dữ liệu chưa được đồng bộ(ví dụ: các kích thước hình ảnh khác nhau, trước tiên cần phải resize lại thông qua hàm
preprocess_img()). shuffle()giữ một bộ đệm về số lượng hình ảnh được phép truyền qua để nó trộn dữ liệu, lý tưởng là con số này sẽ có cùng với số mẫu trong bộ train. Tuy nhiên, nếu tập dữ liệu train quá lớn, bộ đệm này có thể làm tràn bộ nhớ. Thông thường, chúng ta nên sử dụng từ 1000 đến 10000.- Đối với các phương thức gọi số luồng chạy song song
num_parallel_callsvới tham số có sẵn như làmap(), đặt nó thànhnum_parallel_calls = tf.data.AUTOTUNEcải thiện đáng kể tốc độ - Không thể sử dụng
cache()nếu tập dữ liệu không thể phù hợp với bộ nhớ.
📝 Ánh xạ hàm tiền xử lý dữ liệu qua tập dữ liệu -> shuffle dữ liệu -> Đưa dữ liệu vào từng cụm và song song với quá trình này, chắc chắn rằng chuẩn bị cụm tiếp theo (prefetch) để khi xử lý xong cụm này, nó ngay lập tức nhảy qua cụm tiếp theo mà không cần mất thời gian xử lý đưa hình ảnh vào cụm.
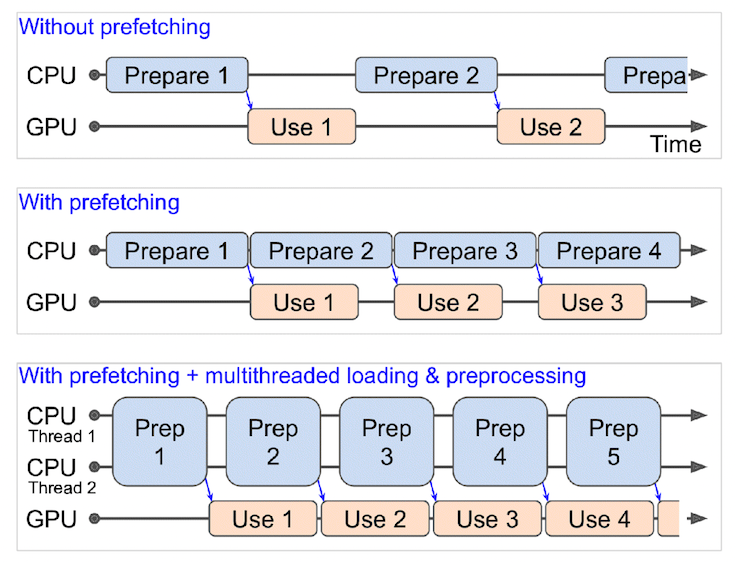
# Train data # Ánh xạ hàm preprocessing_image đến tập dữ liệu train train_data = train_data.map(map_func=preprocessing_image, num_parallel_calls=tf.data.AUTOTUNE) # Xáo trộn dữ liệu, đưa chúng vào theo từng cụm đồng thời chuẩn bị dữ liệu cho cụm sau train_data = train_data.shuffle(buffer_size=1000).batch(batch_size=32).prefetch(tf.data.AUTOTUNE) # ============================= # Test data # Ánh xạ hàm preprocessing_image đến tập dữ liệu train test_data = test_data.map(map_func=preprocessing_image, num_parallel_calls=tf.data.AUTOTUNE) # Với tập dữ liệu test, chúng ta không cần xáo trộn dữ liệu, chỉ cần đưa chúng về từng cụm và chuẩn bị cụm tiếp theo test_data = test_data.batch(batch_size=32).prefetch(buffer_size=tf.data.AUTOTUNE)
train_data, test_data
(<PrefetchDataset shapes: ((None, 224, 224, 3), (None,)), types: (tf.float32, tf.int64)>, <PrefetchDataset shapes: ((None, 224, 224, 3), (None,)), types: (tf.float32, tf.int64)>)
Hình dạng của dữ liệu là một tuple của (image, label) với kiểu dữ liệu (tf.float32, tf.int64)
🔑 Lưu ý: Bạn có thể bỏ qua phương thức
prefetch()tại khâu cuối cùng của quá trình trên. Tuy nhiên, nó sẽ load dữ liệu chậm hơn đáng kể khi mô hình đưa dữ liệu vào trước khi tiến hành học. Vì vậy, hầu hết các đường dẫn vào dữ liệu input của bạn nên kết thúc bằng lệnh gọi đếnprefecth().
5. Tạo callback function của mô hình trước khi bắt đầu xây dựng nó
Vì chúng ta sẽ train trên một lượng lớn dữ liệu và quá trình train này có thể mất nhiều thời gian, nên thiết lập một số hàm callback cho mô hình để chúng ta chắc chắn rằng mô hình sẽ ghi lại quá trình train vào trong các log. Điều này cực kỳ quan trọng để giúp chúng ta có thể xử lý nếu có bất thường hoặc sự cố nào xảy ra trong quá trình mô hình train.
Chúng ta sẽ sử dụng 2 callbacks function :
+ tf.keras.callbacks.TensorBoard() : cho phép chúng ta theo dõi lịch sử train của mô hình, và cũng giúp so sánh với các mô hình train khác.
+ tf.keras.callbacks.ModelCheckPoint() : lưu tiến trình của mô hình trong các khoảng khác nhau, vì vậy chúng ta có thể load và sử dụng lại sau này mà không cần phải train lại.
+ Check point cũng hữu ích để chúng ta có thể bắt đầu tinh chỉnh mô hình của mình tại một thời điểm cụ thể và hoàn tác về trạng thái trước đó nếu việc tinh chỉnh không mang lại hiệu quả.
TensorBoard callback đã được xây dựng sẵn trong utility_functions, bạn có thể sử dụng lại mà không cần viết thêm hàm định nghĩa về nó.
Chúng ta sẽ viết ModelCheckpoint Callback
from utility_functions import create_tensorboard_callback import os checkpoint_path = "model_checkpoints/efficientnetb0_feature_extraction.ckpt" model_checkpoint_cb = tf.keras.callbacks.ModelCheckpoint(checkpoint_path, monitor="val_accuracy", verbose=1, save_best_only=True, save_weights_only=True)
6. Thiết lập train độ chính xác hỗn hợp (mixed precision training)
Thông thường, tensor trong TensorFlow mặc định là kiểu dữ liệu float32 (trừ khi được chỉ định khác).
Trong khoa học máy tính, float32 còn được gọi single-precision floating-point format. 32 có nghĩa là nó thường chiếm 32 bit trong bộ nhớ máy tính.
Vì bộ nhớ của GPU là có hạn, do đó nó chỉ có thể xử lý một số float32 tensors cùng một lúc. Để có thể xử lý nhiều tensors hơn trong cùng bộ nhớ như vậy, thay vì để mỗi phần tử chiếm bộ nhớ đến 32 bit, chúng ta có thể sử dụng kết hợp tensors với float16 và float32 để tận dụng bộ nhớ của GPU tốt hơn.
Đối với tensor ở định dạng float16, mỗi phần tử chiếm 16 bit trong bộ nhớ máy tính. Do đó, nếu sử dụng mixed precision training chúng ta có thể tăng tốc độ load dữ liệu lên đến gấp 3 lần so với kiểu dữ liệu float32.
Để được giải thích chi tiết hơn, bạn có thể đọc qua [TensorFlow mixed precision guide] (https://www.tensorflow.org/guide/mixed_pre precision)

🔑 Lưu ý: Như ở đầu bài viết đã có đề cập, nếu GPU của bạn đang sử dụng không đủ số điểm được đánh giá (7.0),
mixed precision trainingsẽ không hoạt động. (Xem: "Supported Hardware" trong the mixed precision guide để biết thêm thông tin).
Chúng ta sẽ sử dụng API tensorflow.keras.mixed_pre precision để thực hiện.
Đầu tiên, chúng ta sẽ import API và sau đó sử dụng phương thức set_global_policy() để thiết lập dtype policy thành float16.
from tensorflow.keras import mixed_precision
mixed_precision.set_global_policy(policy="mixed_float16")
mixed_precision.global_policy()
<Policy "mixed_float16">
mô hình của chúng ta sẽ tự động tận dụng các biến float16 nếu có thể và lần lượt tăng tốc độ train.
7. Xây dựng mô hình trích xuất đặc trưng
Bởi vì tập dữ liệu khá lớn, chúng ta sẽ sử dụng mô hình được train trước đó (EfficienetNetB0). Đầu tiên, chúng ta sẽ giữ nguyên các trọng số (đặc trưng) của mô hình này.
Nhắc lại, thứ tự cụ thể để sử dụng học chuyển tiếp là: + 1. Xây dựng mô hình trích xuất đặc trưng (chỉ thay đổi layer trên cùng cho phù hợp với output) + 2. Train một vài epoch với số layer thấp hơn bị đóng băng (không cho phép thay đổi trọng số của layer đó) + 3. Tinh chỉnh một số layer ở trên cùng nếu cần thiết.
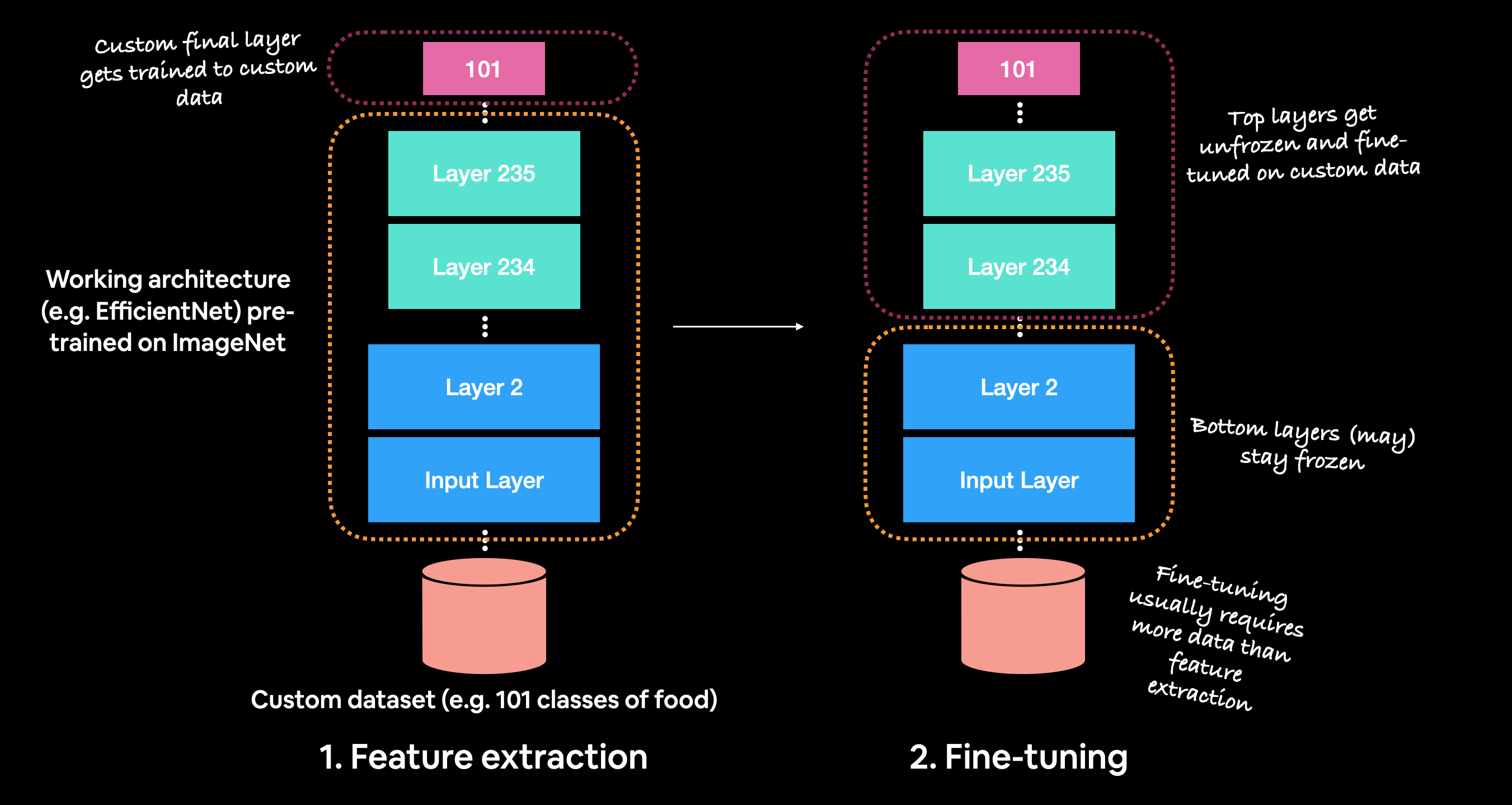
Để xây dựng mô hình trích xuất đặc tính, chúng ta sẽ sử dụng :
+ Mô hình EfficientNetB0 từ tf.keras.applications được train trước trong ImageNet làm mô hình cơ sở.
+ Tải xuống mô hình này và loại bỏ top layer bằng tham số include_top = False để chúng ta có thể tạo các output phù hợp với dữ liệu hiện tại.
+ Cố định các layer trong base_model để mô hình tận dụng lại các trọng số đã được train trước đó
+ Compile mô hình, nếu label chưa được onehot thì sử dụng loss=sparse_categorical_crossentropy, còn nếu đã onehot rồi thì loss=categorical_crossentropy. Trong trường hợp của chúng ta, chúng ta để label dưới dạng label-encoded trong hàm preprocessing_image
+ Fit mô hình trong 3 epoch cùng với sử dụng callback function TensorBoard và ModelCheckpoint.
🔑 Lưu ý: Vì đang sử dụng
mixed precision training, mô hình cần tách biệt output layer với phần layer còn lại. VD :layers.Activation("softmax", dtype=tf.float32). Điều này đảm bảo output của mô hình được trả về đúng kiểufloat32với độ chính xác ổn định với kiểu dữ liệufloat16( chỉ quan trọng đối với tính toán sai số). Xem thêm tại "Building the model".

from tensorflow.keras import Model, Sequential, layers
base_model = tf.keras.applications.EfficientNetB0(include_top=False) base_model.trainable = False
INPUT_SHAPE=(224,224,3) inputs = layers.Input(shape=INPUT_SHAPE, name="input_layer") x = base_model(inputs, training=False) x = layers.GlobalAveragePooling2D()(x) # Tách activation của output layer để có thể định nghĩa kiểu float32 cho activation x = layers.Dense(len(class_names))(x) outputs = layers.Activation(activation="softmax", dtype=tf.float32)(x) model = Model(inputs, outputs) model.compile( loss="sparse_categorical_crossentropy", optimizer="adam", metrics=["accuracy"] )
model.summary()
Model: "model" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_layer (InputLayer) [(None, 224, 224, 3)] 0 _________________________________________________________________ efficientnetb0 (Functional) (None, None, None, 1280) 4049571 _________________________________________________________________ global_average_pooling2d (Gl (None, 1280) 0 _________________________________________________________________ dense (Dense) (None, 101) 129381 _________________________________________________________________ activation (Activation) (None, 101) 0 ================================================================= Total params: 4,178,952 Trainable params: 129,381 Non-trainable params: 4,049,571 _________________________________________________________________
Trước khi tiến hành fit mô hình trên, chúng ta sẽ kiểm tra lại kiểu dữ liệu của các layer trong mô hình.
for layer in model.layers : print(layer.name, layer.trainable, layer.dtype, layer.dtype_policy)
input_layer True float32 <Policy "float32"> efficientnetb0 False float32 <Policy "mixed_float16"> global_average_pooling2d True float32 <Policy "mixed_float16"> dense True float32 <Policy "mixed_float16"> activation True float32 <Policy "float32">
Qua phần trên chúng ta thấy:
+ layer.name : Tên của layer
+ layer.trainable : liệu một layer có thể train được hay không (tất cả các layer đều có thể train được ngoại trừ efficientnetb0 vì chúng ta đã thiết lập trainable=False ở phía trên)
+ layer.dtype : kiểu dữ liệu mà layer lưu trữ các biến trong nó.
+ layer.dtype_policy : Kiểu dữ liệu layer tính toán bên trong.
🔑 Lưu ý: Một layer có thể có kiểu dữ liệu là
float32nhưng kiểu dữ liệu policy làmixed_float16vì nó lưu trữ giá trị của các biến làfloat32(ổn định hơn), nhưng khi thực hiện tính toán nó sẽ sử dụng kiểufloat16(nhanh hơn).
Kiểm tra chi tiết kiểu dữ liệu trong base_model(efficiennetb0)
for layer_index, layer in enumerate(model.layers[1].layers) : print(layer_index, layer.name, layer.dtype, layer.dtype_policy)
0 input_1 float32 <Policy "float32"> 1 rescaling float32 <Policy "mixed_float16"> 2 normalization float32 <Policy "mixed_float16"> ... 233 block7a_project_bn float32 <Policy "mixed_float16"> 234 top_conv float32 <Policy "mixed_float16"> 235 top_bn float32 <Policy "mixed_float16"> 236 top_activation float32 <Policy "mixed_float16">
INITIAL_EPOCH = 3 model_feature_extraction_history = model.fit( train_data, steps_per_epoch=len(train_data), epochs=INITIAL_EPOCH, validation_data=test_data, validation_steps=int(0.25 * len(test_data)), callbacks=[ create_tensorboard_callback("transfer_learning","efficientnetb0_feature_extraction"), model_checkpoint_cb ] )
Epoch 1/3 2368/2368 [==============================] - 318s 116ms/step - loss: 1.8197 - accuracy: 0.5575 - val_loss: 1.2282 - val_accuracy: 0.6778 ... Epoch 3/3 2368/2368 [==============================] - 262s 110ms/step - loss: 1.1433 - accuracy: 0.7024 - val_loss: 1.0920 - val_accuracy: 0.7056 Epoch 00003: val_accuracy improved from 0.69797 to 0.70558, saving model to model_checkpoints/efficientnetb0_feature_extraction.ckpt
Chúng ta sẽ tiến hành đánh giá trên toàn bộ dữ liệu test
result_model_feature_extraction = model.evaluate(test_data) result_model_feature_extraction
790/790 [==============================] - 84s 107ms/step - loss: 1.0935 - accuracy: 0.7052 [1.0935087203979492, 0.7052277326583862]
Sau khi train 3 epochs, khả năng dự đoán của mô hình đạt độ chính xác khoảng ~71%.
Và vì mô hình có sử dụng ModelCheckpoint callback nên đã lưu lại những trọng số mà mô hình học tốt nhất. Bây giờ, chúng ta sẽ load lại chúng. Để giữ cho model không bị thay đổi, chúng ta sẽ tạo một bản sao cho model và tiến hành load các weight vào bản sao này.
Load và đánh giá trọng số trong model checkpoint
Chúng ta có thể load và đánh giá các giá trị kiểm tra của mô hình theo các bước sau:
+ Tạo bản sao (clone) của mô hình bằng tf.keras.models.clone_model() để sao chép mô hình trích xuất đặc trưng với các trọng số được reset.
+ Gọi phương thức load_weights() trên mô hình bản sao và truyền đường dẫn đến nơi lưu giữ các trọng số đã được kiểm tra.
+ Gọi evaluate với dữ liệu test để đánh giá mô hình.
Các kiểm tra (checkpoint) này rất hữu ích khi bạn thực hiện một thử nghiệm, chẳng hạn như tinh chỉnh mô hình của mình. Trong trường hợp bạn tinh chỉnh mô hình trích xuất đặc trưng của mình và thấy nó không mang lại bất kỳ cải thiện nào, bạn có thể hoàn tác về phiên thời điểm kiểm tra của mô hình của mình.
cloned_model = tf.keras.models.clone_model(model) cloned_model.summary()
Model: "model" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_layer (InputLayer) [(None, 224, 224, 3)] 0 _________________________________________________________________ efficientnetb0 (Functional) (None, None, None, 1280) 4049571 _________________________________________________________________ global_average_pooling2d (Gl (None, 1280) 0 _________________________________________________________________ dense (Dense) (None, 101) 129381 _________________________________________________________________ activation (Activation) (None, 101) 0 ================================================================= Total params: 4,178,952 Trainable params: 129,381 Non-trainable params: 4,049,571 _________________________________________________________________
cloned_model.load_weights("model_checkpoints/efficientnetb0_feature_extraction.ckpt")
Mỗi lần bạn thực hiện thay đổi đối với mô hình của mình (bao gồm cả việc load các trọng số), bạn phải biên dịch lại.
cloned_model.compile( loss="sparse_categorical_crossentropy", optimizer="adam", metrics=["accuracy"] )
results_cloned_model_with_load_weights = model.evaluate(test_data) results_cloned_model_with_load_weights
790/790 [==============================] - 78s 98ms/step - loss: 1.0935 - accuracy: 0.7052 [1.0935101509094238, 0.7052277326583862]
So sánh kết quả kiểm định của mô hình trên dữ liệu test của bản gốc và bản sao xem chúng có tương đồng với nhau hay không
results_cloned_model_with_load_weights == result_model_feature_extraction
False
Ồ, có vẻ như 2 kết quả này không chính xác tuyệt đối, chúng ta sẽ sử dụng np.isclose() để đánh giá tương đối giữa 2 giá trị này.
import numpy as np assert np.isclose(result_model_feature_extraction, results_cloned_model_with_load_weights).all()
OK, 2 giá trị trên đã giống với nhau tương đối
Việc sao chép mô hình chỉ bảo toàn các layer của dtype_policy (nhưng không bảo toàn trọng số) vì vậy nếu chúng ta muốn tiếp tục tinh chỉnh với mô hình đã nhân bản, chúng ta có thể sử dụng kiểu dữ liệu mixed precision dtype policy
for layer in cloned_model.layers[1].layers : print(layer.name, layer.dtype, layer.dtype_policy)
input_1 float32 <Policy "float32"> rescaling float32 <Policy "mixed_float16"> normalization float32 <Policy "mixed_float16"> ... top_conv float32 <Policy "mixed_float16"> top_bn float32 <Policy "mixed_float16"> top_activation float32 <Policy "mixed_float16">
Lưu toàn bộ mô hình thành file
Chúng ta cũng có thể lưu toàn bộ mô hình bằng phương thức save().
Vì mô hình khá lớn, bạn có thể muốn lưu nó vào Google Drive (nếu bạn đang sử dụng Google Colab) để bạn có thể tải nó vào để sử dụng sau này.
from google.colab import drive drive.mount('/content/drive')
save_google_drive_dir = "drive/MyDrive/transfer_learning/101_classes_food_model" model.save(save_google_drive_dir)
Bạn cũng có thể lưu mô hình trực tiếp trên Google Colab
🔑Lưu ý : Bộ nhớ của Google Colab là tạm thời và mô hình của bạn sẽ tự xóa (cùng với mọi tệp đã lưu khác) khi phiên Colab hết hạn.
model.save("efficientnetB0_feature_extraction_model")
Load mô hình vừa tải xuống
loaded_model = tf.keras.models.load_model("efficientnetB0_feature_extraction_model") loaded_model.summary()
Model: "model" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_layer (InputLayer) [(None, 224, 224, 3)] 0 _________________________________________________________________ efficientnetb0 (Functional) (None, None, None, 1280) 4049571 _________________________________________________________________ global_average_pooling2d (Gl (None, 1280) 0 _________________________________________________________________ dense (Dense) (None, 101) 129381 _________________________________________________________________ activation (Activation) (None, 101) 0 ================================================================= Total params: 4,178,952 Trainable params: 129,381 Non-trainable params: 4,049,571 _________________________________________________________________
Kiểm định dữ liệu test của loaded_model xem nó có hoạt động chính xác hay chưa
result_loaded_model = loaded_model.evaluate(test_data) result_loaded_model
790/790 [==============================] - 82s 101ms/step - loss: 1.0935 - accuracy: 0.7052 [1.093510389328003, 0.7052277326583862]
So sánh kết quả kiểm định giữa loaded_model và model
assert np.isclose(result_model_feature_extraction, result_loaded_model).all()
loaded_model đã hoạt động đúng.
8. Tinh chỉnh mô hình trích xuất đặc trưng
Chúng ta sẽ quay lại với model để tiến hành tinh chỉnh mô hình. Nếu như đến phần này, có xảy ra sự cố hoặc bị ngắt kết nối... khiến cho notebook không hoạt động phải train lại từ đầu thì bạn có thể bỏ qua bước train mô hình trên, chỉ cần tải mô hình vừa được save ở trên và tiến hành tinh chỉnh mô hình như dưới đây.
Ở bài viết này sẽ chọn cách tải xuống mô hình để thực hiện tinh chỉnh mô hình.
!wget https://www.dropbox.com/s/7m1pspkxbebt6o8/101_classes_food_model.zip
unzip_file("101_classes_food_model.zip")
Unzipped file
loaded_model = tf.keras.models.load_model("101_classes_food_model")
Kiểm tra quá trình đánh giá của mô hình :
loaded_model.evaluate(test_data)
790/790 [==============================] - 81s 100ms/step - loss: 1.0921 - accuracy: 0.7053 [1.0920672416687012, 0.7053465247154236]
Kết quả kiểm định của mô hình được tải xuống đã giống với model trên dữ liệu test.
Có bao nhiêu layer trong loaded_model?
for layer in loaded_model.layers : print(layer.name, layer.trainable)
input_layer True efficientnetb0 False global_average_pooling2d True dense True activation True
for layer in loaded_model.layers[1].layers : print(layer.name, layer.trainable)
input_1 True rescaling False normalization False stem_conv_pad False ... block7a_project_conv False block7a_project_bn False top_conv False top_bn False top_activation False
Thiết lập cho phép mọi layer có thể train.
for layer in loaded_model.layers : layer.trainable = True print(layer.name, layer.trainable)
input_layer True efficientnetb0 True global_average_pooling2d True dense True activation True
Kiểm tra trong layer efficientnetB0 đã mở cho phép train chưa
for layer in loaded_model.layers[1].layers: print(layer.name, layer.trainable)
input_1 True rescaling True normalization True stem_conv_pad True ... block7a_se_excite True block7a_project_conv True block7a_project_bn True top_conv True top_bn True top_activation True
Chúng ta sẽ định nghĩa lại ModelCheckpoint callback, lần này sẽ chỉ lưu giá trị tốt nhất của mô hình vì mô hình sắp tới chúng ta sẽ train đến khi nó có kết quả tốt nhất, không cần thiết phải lưu các trọng số nữa vì nó chỉ có ích khi muốn cải thiện mô hình.
checkpoint_path = "model_checkpoints/model_fine_tune.ckpt" model_checkpoint_cb = tf.keras.callbacks.ModelCheckpoint( checkpoint_path, monitor="val_loss", verbose=1, save_best_only=True, save_weights_only=False )
Hiện tại mô hình học có hơn 200 layer và sử dụng gần 100.000 hình ảnh (75k+ train, 5k+ test), có nghĩa là thời gian train của mô hình có thể sẽ lâu hơn nhiều so với trước đây.
🤔 Câu hỏi: Thời gian train là bao lâu?
Trung bình 1 epoch có thể mất đến 5ph, nếu train với 100 epoch thì con số đó rơi vào khoảng 500ph tức là hơn 8 giờ đồng hồ. Trong trường hợp của DeepFood paper (đường cơ sở mà mô hình sắp tới đây đang cố gắng đánh bại), mô hình hoạt động tốt nhất của họ mất 2-3 ngày để train.
Bạn thực sự sẽ chỉ biết mất bao lâu khi bạn bắt đầu train qua một vài epoch để ước tính được thời gian tương đối của nó.
🤔 Câu hỏi: Có nên ngừng train khi mô hình không còn tiến bộ nữa không?
Lý tưởng nhất là khi mô hình của ngừng cải thiện. Nhưng một lần nữa, do bản chất của học sâu, có thể khó biết khi nào chính xác một mô hình sẽ ngừng cải tiến.
May mắn thay, có một giải pháp: gọi lại ` EarlyStopping.
Hàm callback EarlyStopping giám sát hiệu suất mô hình cụ thể (ví dụ:val_loss) và khi nó ngừng cải thiện trong một số epoch, sẽ tự động dừng train.
Sử dụng EarlyStopping kết hợp với ModelCheckpoint tự động lưu mô hình hoạt động tốt nhất, chúng ta có thể tiếp tục train mô hình của mình với số lượng không giới hạn cho đến khi nó ngừng cải thiện.
early_stopping_cb = tf.keras.callbacks.EarlyStopping(patience=3,verbose=1)
Nếu bạn đang có kế hoạch train các mô hình lớn, thì ModelCheckpoint và EarlyStopping là hai callback function mà bạn sẽ thường xuyên gặp nhất.
Khi mô hình bắt đầu cho thấy khả năng tiếp thu giảm dần, chúng ta sẽ làm gì để mô hình có thể tiếp thu tốt hơn? Đó chính là learning_rate. Nếu learning_rate càng lớn thì mô hình học sẽ lướt qua nhiều kiến thức trong dữ liệu, nhưng khi nó càng nhỏ thì mô hình sẽ học chi tiết hơn, học sâu hơn và lâu hơn.
Khi val_loss ngừng cải thiện trong hai hoặc nhiều epoch, chúng ta sẽ giảm learning_rate xuống bằng 5 lần so với số trước đó (ví dụ: 0,001 xuống thành 0.001 / 5 = 0,0002).
Và để đảm bảo learning_rate không quá thấp (có thể dẫn đến việc mô hình không học được gì), chúng ta sẽ đặt tạo một learning_rate tối thiểu để nó không thể bước qua là 1e-6.
reduce_lr_cb = tf.keras.callbacks.ReduceLROnPlateau( monitor="val_loss", factor=0.1, patience=10, verbose=1, min_lr=1e-6 )
FINE_TUNE_EPOCHS = 100 loaded_model.compile( loss="sparse_categorical_crossentropy", optimizer=tf.keras.optimizers.Adam(learning_rate=0.0001), metrics=["accuracy"] ) loaded_model_fine_tune_history = loaded_model.fit( train_data, steps_per_epoch=len(train_data), epochs=FINE_TUNE_EPOCHS, validation_data=test_data, validation_steps=len(test_data), callbacks=[ create_tensorboard_callback("transfer_learning", "efficientnetb0_feature_extraction"), early_stopping_cb, model_checkpoint_cb, reduce_lr_cb ] )
Epoch 1/100 2368/2368 [==============================] - 1272s 522ms/step - loss: 0.9187 - accuracy: 0.7538 - val_loss: 0.8164 - val_accuracy: 0.7726 Epoch 00001: val_loss improved from inf to 0.81644, saving model to model_checkpoints/model_fine_tune.ckpt INFO:tensorflow:Assets written to: model_checkpoints/model_fine_tune.ckpt/assets INFO:tensorflow:Assets written to: model_checkpoints/model_fine_tune.ckpt/assets /usr/local/lib/python3.7/dist-packages/keras/utils/generic_utils.py:497: CustomMaskWarning: Custom mask layers require a config and must override get_config. When loading, the custom mask layer must be passed to the custom_objects argument. category=CustomMaskWarning) ... Epoch 00005: val_loss did not improve from 0.79069 Epoch 00005: early stopping
results_loaded_model_fine_tune = loaded_model.evaluate(test_data) results_loaded_model_fine_tune
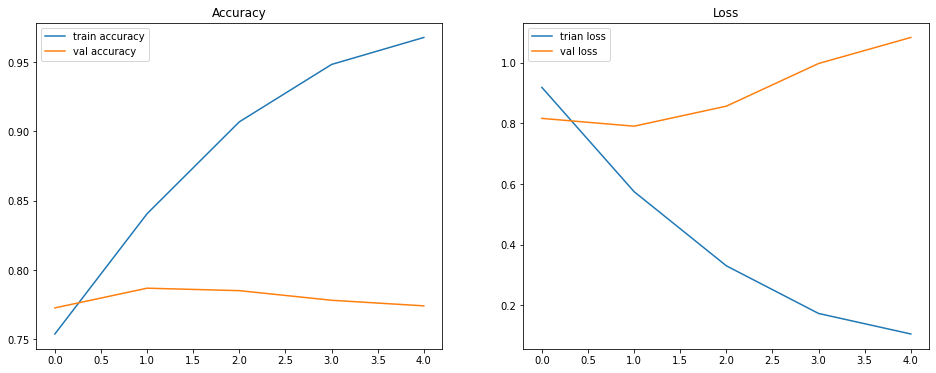
790/790 [==============================] - 79s 100ms/step - loss: 1.0836 - accuracy: 0.7741 [1.083551287651062, 0.7740989923477173]
plot_loss_curves(loaded_model_fine_tune_history)
Sau quá trình train và đánh giá mô hình, chúng ta sẽ lưu mô hình lại.
loaded_model_save_dir = "/content/drive/MyDrive/transfer_learning/101_classes_food_fine_tune" loaded_model.save(loaded_model_save_dir)
Phần tiếp theo sẽ tiến hành dự đoán, đánh giá và phân tích các yếu tố trong mô hình. Các bạn đón xem nhé.