Deep Learning với Tensorflow Module 6 phần 2.2: Transfer learning Điều chỉnh mô hình
Ở phần trước chúng ta đã thực hiện 4 bước xây dựng mô hình transfer learning tinh chỉnh. Trong phần này chúng ta sẽ tiếp tục
Nội dung trong phần này :
5. Thử nghiệm mô hình hóa trên dữ liệu food
+ 5.1. Model 1 : Xây dựng mô hình transfer learning trích xuất đặc trưng trên 1% dữ liệu được tăng tính đa dạng (data augmentation)
+ 5.2. Model 2 : Xây dựng mô hình transfer learning trích xuất đặc trưng trên 10% dữ liệu được tăng tính đa dạng (data augmentation)
+ Giới thiệu hàm callback ModelCheckpoint để lưu kết quả train
+ 5.3. Model 0 : Xây dựng mô hình transfer learning được tinh chỉnh trên 10% dữ liệu train ban đầu
+ 5.4. Model 2 : Xây dựng mô hình transfer learning được tinh chỉnh trên 10% dữ liệu trainđược tăng tính đa dạng.
+ 5.5. Model 2 : Xây dựng mô hình transfer learning được tinh chỉnh trên toàn bộ dữ liệu train được tăng tính đa dạng.
6. So sánh kết quả thử nghiệm mô các mô hình hình bằng TensorBoard
5. Thử nghiệm mô hình hóa trên dữ liệu food
5.1 Model 1 : Xây dựng mô hình transfer learning trích xuất đặc trưng trên 1% dữ liệu đa tăng cường tính đa dạng (data augmentation)
Trước tiên chúng ta sẽ tải tập dữ liệu chứa 1% trong tổng dữ liệu đã được thực hiện trong module 4: preprocessing data
!wget https://www.dropbox.com/s/dryeebi147n37ra/10_food_classes_1_percent.zip
10_food_classes_1_p 100%[===================>] 122.75M 78.4MB/s in 1.6s 2021-09-10 02:06:41 (78.4 MB/s) - ‘10_food_classes_1_percent.zip.1’ saved [128714735/128714735]
unzip_file("/content/10_food_classes_1_percent.zip")
Unzipped file
walk_through_directory("10_food_classes_1_percent")
Có 2 thư mục và 0 tập tin trong thư mục 10_food_classes_1_percent Có 10 thư mục và 0 tập tin trong thư mục 10_food_classes_1_percent/test ... Có 0 thư mục và 7 tập tin trong thư mục 10_food_classes_1_percent/train/garlic_bread Có 0 thư mục và 7 tập tin trong thư mục 10_food_classes_1_percent/train/clam_chowder
- Tập dữ liệu train hiên tại mỗi class chỉ có 1% dữ liệu tức là chỉ có 7 hình để train cho 1 class.
- Tập dữ liệu test không có gì thay đổi so với 10% dữ liệu như trên.
train_dir_1_percent_data_10_class = "10_food_classes_1_percent/train" test_dir_1_percent_data_10_class = "10_food_classes_1_percent/test"
train_data_1_percent = image_dataset_from_directory( train_dir_1_percent_data_10_class, image_size=(224,224), batch_size=32, label_mode="categorical" ) test_data = image_dataset_from_directory( test_dir_1_percent_data_10_class, image_size=(224,224), batch_size=32, label_mode="categorical" )
Found 70 files belonging to 10 classes. Found 2500 files belonging to 10 classes.
train_data_1_percent.class_names
['bruschetta', 'clam_chowder', 'filet_mignon', 'garlic_bread', 'greek_salad', 'pad_thai', 'panna_cotta', 'prime_rib', 'pulled_pork_sandwich', 'spaghetti_bolognese']
Kiểm tra xem class names của mô hình 1% dữ liệu có khác với 10% dữ liệu hay không
class_names_10_percent_data = train_data_10_percent.class_names class_names_1_percent_data = train_data_1_percent.class_names assert set(class_names_10_percent_data) == set(class_names_1_percent_data)
Nếu class_names của 2 tập dữ liệu khác nhau, nó sẽ lập tức báo lỗi
input_shape = (224,224,3) base_model = tf.keras.applications.EfficientNetB0(include_top=False) base_model.trainable = False # Tạo input layer inputs = layers.Input(shape=input_shape, name="input_layer") # Tăng tính đa dạng cho inputs trên augmented_inputs = data_augmentation(inputs) # Chuẩn hóa dữ liệu inputs (đối với EfficientNetB0 thì bỏ qua bước này) # normed_inputs = layers.Rescaling(scale=1/255.) # Đưa augmented_inputs vào mô hình base_model x = base_model(augmented_inputs) # Nhóm các output đặc trưng của mô hình cơ sở global_avg_pool_2d = layers.GlobalAveragePooling2D(name="global_avg_pool_2d")(x) # Đặt một dense layer như là outputs outputs = layers.Dense(len(class_names), activation="softmax", name="output_layer")(global_avg_pool_2d) # Tạo mô hình với 2 tham số inputs và outputs model_1 = Model(inputs, outputs) # Biên dịch mô hình với các hàm loss, kỹ thuật tối ưu hóa và phương pháp đo lường cho mô hình model_1.compile( loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"] ) # Fit mô hình model_1_history = model_1.fit( train_data_1_percent, steps_per_epoch=len(train_data_1_percent), epochs=5, validation_data=test_data, validation_steps=int(0.25*len(test_data)), callbacks=[ create_tensorboard_callback("transfer_learning_fine_tuning", "efficientB0_1_percent_data_augmentation") ] )
Đã lưu tensorboard vào transfer_learning_fine_tuning/efficientB0_1_percent_data_augmentation/10092021-020646 Epoch 1/5 ... Epoch 5/5 3/3 [==============================] - 7s 3s/step - loss: 1.6743 - accuracy: 0.6143 - val_loss: 1.8225 - val_accuracy: 0.4391
Mô hình chỉ sử dụng 1% dữ liệu (7 hình ảnh đã được biến dạng ở mỗi class) để train, nhưng với số lượng hình ảnh ít ỏi đó, nó vẫn cho ra kết quả dự đoán rất tốt so với 50,67% của mô hình original Food-101 paper nhưng được train với tất cả dữ liệu.
Kiến trúc tổng quan của model_1
model_1.summary()
Model: "model_1" ================================================================= Total params: 4,062,381 Trainable params: 12,810 Non-trainable params: 4,049,571 _________________________________________________________________
Trong mô hình đã có data_augmentation là một layer được tích hợp ngay trong mô hình. Điều này cũng có nghĩa là khi chúng ta lưu lại mô hình này và load nó ở bất kỳ nơi nào khác thì data augmentation layers này vẫn gắn liền với mô hình.
Một điều quan trọng nữa là data augmentation chỉ chạy trong quá trình train Vì vậy, nếu chúng ta đánh giá hoặc sử dụng mô hình của dự đoán một class nào đó của một hình ảnh, thì các data augmentation layer sẽ tự động ngắt.
results_1_percent_data_aug = model_1.evaluate(test_data) results_1_percent_data_aug
79/79 [==============================] - 11s 133ms/step - loss: 1.8288 - accuracy: 0.4368 [1.8288201093673706, 0.4368000030517578]
Kết quả ở đây có thể tốt hơn hoặc kém hơn một chút so với kết quả đầu ra của nhật ký của mô hình của chúng ta trong quá trình train, vì trong lúc train chúng ta chỉ đánh giá mô hình của mình trên 25% dữ liệu test bằng cách sử dụng dòng validation_steps = int(0,25 * len (test_data)). Việc rút ngắn số lượng dữ liệu test trong lúc train giúp tiết kiệm thời gian xử lý của mô hình.
Tiếp theo, kiểm tra learning curves mà mô hình học qua mỗi epoch:
plot_loss_curves(model_1_history)
Có vẻ như các chỉ số đo lường hiệu suất trên cả hai tập dữ liệu có cùng quỹ đạo, hướng đi khá tương đồng nhau, và có khả năng mô hình sẽ cải thiện thêm nếu chúng ta tiếp tục train lâu hơn. Nhưng chúng ta sẽ chuyển sang train kiểu dữ liệu khác thay vì train lâu hơn như vậy.
5.2. Model 2 : Xây dựng mô hình transfer learning trích xuất đặc trưng trên 10% dữ liệu đa tăng cường tính đa dạng (data augmentation)
Ở phần này chúng ta đã download tập dữ liệu trước đó để train model_0, nên không cần phải thực hiện các bước tải dữ liệu và khám phá khái quát thành phần của tập dữ liệu đó. Chúng ta sẽ xây dựng mô hình luôn. Phần này sẽ không giải thích lại vì nó tương tự như mô hình trên, bạn có thể tham khảo mô hình trên để nắm rõ hơn.
IMAGE_SHAPE=(224,224,3) base_model = tf.keras.applications.EfficientNetB0(include_top=False) base_model.trainable = False inputs = layers.Input(shape=IMAGE_SHAPE, name="input_layer") augmented_inputs = data_augmentation(inputs) x = base_model(augmented_inputs) global_avg_pooling_2d = layers.GlobalAveragePooling2D()(x) outputs = layers.Dense(len(class_names), activation="softmax", name="outputs")(global_avg_pooling_2d) model_2 = Model(inputs, outputs) model_2.compile( loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"] )
Giới thiệu hàm callback ModelCheckpoint để lưu kết quả train
Trong mô hình này, để tăng thêm sự mới mẻ chúng ta sẽ thêm một callback function có tên ModelCheckpoint.
ModelCheckpoint callback cung cấp cho bạn khả năng lưu lại hoặc toàn bộ mô hình theo định dạng SavedModel hoặc chỉ lưu trọng số (mẫu) vào một thư mục được chỉ định khi nó đào tạo.
Điều này rất hữu ích nếu bạn nghĩ rằng mô hình của mình sẽ được train trong một thời gian dài nhưng không thể train được liên tục và bạn muốn sao lưu mô hình đã train lại. Điều đó cũng có nghĩa nếu bạn nghĩ rằng mô hình của mình có thể tốt hơn khi được train lâu hơn, thì bạn có thể tải lại mô hình đó từ vị trí đã lưu và tiếp tục train tiếp thay vì phải train lại từ đầu.
Ví dụ: giả sử bạn fit mô hình transfer learning trích xuất đặc trưng trong 5 epochs. Khi bạn kiểm tra các đường learning curves và thấy nó vẫn đang được cải thiện, lúc đó bạn muốn xem liệu việc tinh chỉnh thêm 5 epoch nữa liệu có thể tốt hơn được không. Lúc này, bạn có load hàm callback checkpoint, giải nén một số (hoặc tất cả) các layer của mô hình cơ sở và sau đó tiếp tục train. Trên thực tế, đó chính xác là những gì chúng ta sẽ làm.
Nhưng trước tiên, chúng ta sẽ tạo hàm ModelCheckpoint để chỉ định một thư mục mà chúng ta muốn lưu vào.
def create_checkpoint_callback(checkpoint_dir, experiment_name) : checkpoint_path = os.path.join(checkpoint_dir, experiment_name +".ckpt") model_checkpoint_cb = tf.keras.callbacks.ModelCheckpoint(checkpoint_path, monitor="val_loss", verbose=1, save_weights_only=True, # Chỉ lưu trọng số, nếu False sẽ save toàn bộ mô hình save_best_only=False, #True để save mô hình nào là tốt nhất, save_freq="epoch" #lưu sau mỗi epoch ) print(f"Đã lưu checkpoint callback tại :{checkpoint_path}") return model_checkpoint_cb
🤔 Câu hỏi: Lưu toàn bộ mô hình (định dạng SavedModel) và chỉ lưu trọng số có gì khác nhau?
Định dạng SavedModel lưu toàn bộ kiến trúc, trọng số và cấu hình train của mô hình vào trong một thư mục. Nó giúp bạn dễ dàng tải lại mô hình của mình một cách chính xác như thế nào ở nơi khác. Tuy nhiên, nếu bạn không muốn chia sẻ tất cả những thông tin chi tiết này với người khác, bạn có thể chỉ muốn lưu và chia sẻ trọng số (đây sẽ chỉ là những con số lớn không thể giải thích được bởi con người). Nếu dung lượng ổ đĩa là một vấn đề, chỉ lưu trọng số sẽ nhanh hơn và chiếm ít dung lượng hơn so với lưu toàn bộ mô hình.
Bởi vì chúng ta sẽ tinh chỉnh nó sau đó, nên chúng ta sẽ tạo một biến initial_epochs và đặt nó là 5 để sử dụng sau này.
initial_epochs = 5 model_2_history = model_2.fit( train_data_10_percent, epochs=initial_epochs, steps_per_epoch=len(train_data_10_percent), validation_data=test_data, validation_steps=int(0.25 * len(test_data)), callbacks=[ create_tensorboard_callback("transfer_learning_fine_tuning", "efficientB0_10_percent_data_augmentation"), create_checkpoint_callback(checkpoint_dir="checkpoints",experiment_name="model_2_10_percent_data_aug") ] )
Epoch 1/5 24/24 [==============================] - 29s 879ms/step - loss: 1.9575 - accuracy: 0.3573 - val_loss: 1.4083 - val_accuracy: 0.6546 Epoch 00001: saving model to checkpoints/model_2_10_percent_data_aug.ckpt ... Epoch 5/5 24/24 [==============================] - 14s 581ms/step - loss: 0.7580 - accuracy: 0.8040 - val_loss: 0.6536 - val_accuracy: 0.8158 Epoch 00005: saving model to checkpoints/model_2_10_percent_data_aug.ckpt
Đánh giá mô hình với test_data
result_10_percent_data_aug = model_2.evaluate(test_data) result_10_percent_data_aug
79/79 [==============================] - 11s 131ms/step - loss: 0.6307 - accuracy: 0.8252 [0.6307364106178284, 0.8252000212669373]
Vẽ đường learning curves của mô hình
plot_loss_curves(model_2_history)
Với 10% dữ liệu ở mỗi class ( tức chỉ chỉ gấp 10 dữ liệu cho mỗi class) mô hình đã đạt được độ chính xác đáng kinh ngạc. Dù model_0 và model_2 có cùng dữ liệu và model_0 có độ chính xác cao hơn so với model_2 nhưng nếu để ngăn chặn overfitting cho mô hình, thì bạn cần chọn model_2. Ngoài ra, các đường cong đang có xu hướng đi đúng hướng, nghĩa là nếu chúng tôi train lâu hơn, các chỉ số của nó có thể sẽ được cải thiện theo hướng tốt như vậy.
Để load những trọng số mà mô hình đã lưu, bạn có thể sử dụng phương thức load_weights(), chuyển nó đến đường dẫn nơi lưu trữ trọng só đó.
model_2.load_weights("checkpoints/model_2_10_percent_data_aug.ckpt")
<tensorflow.python.training.tracking.util.CheckpointLoadStatus at 0x7f0ad8d4be10>
Lúc này mô hình đã load các trọng số được lưu tại checkpoints/model_2_10_percent_data_aug.ckpt
loaded_weights_model_results = model_2.evaluate(test_data)
79/79 [==============================] - 11s 134ms/step - loss: 0.6307 - accuracy: 0.8252
Bây giờ chúng ta sẽ so sánh kết quả của mô hình được train trước đó với mô hình được tải lên. Các kết quả này sẽ rất gần nếu không muốn nói là hoàn toàn giống nhau. Lý do cho những khác biệt nhỏ là do mức độ chính xác của các con số được tính toán.
result_10_percent_data_aug
[0.6307364106178284, 0.8252000212669373]
loaded_weights_model_results
[0.6307364106178284, 0.8252000212669373]
result_10_percent_data_aug == loaded_weights_model_results
True
5.3. Model 0 tinh chỉnh : Xây dựng mô hình transfer learning được tinh chỉnh trên 10% dữ liệu train ban đầu
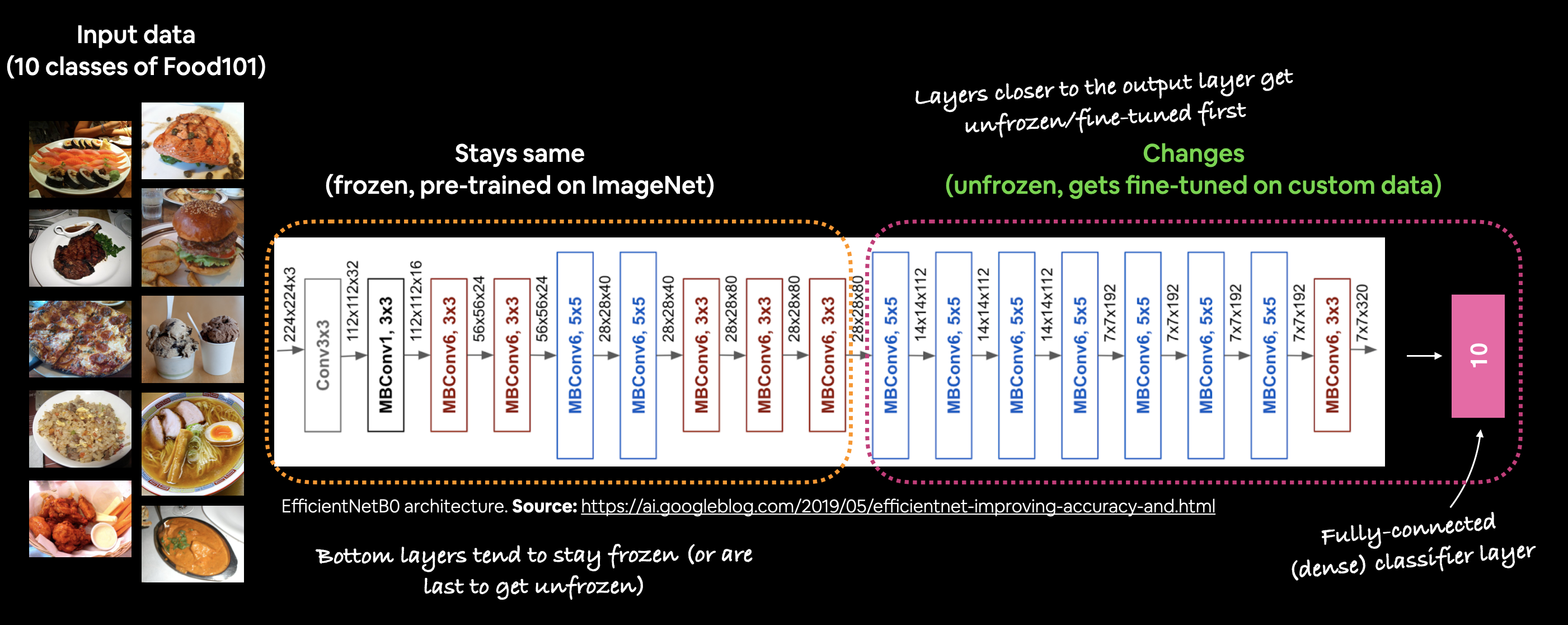
Ở những mô hình transfer learning trích xuất đặc trưng trước, chúng ta đã train 10% dữ liệu gốc và dữ liệu được tăng cường tính đa dạng với 5 epoch. Các layer trong base_model chúng ta chưa hề đả động đến, nó vẫn được sử dụng toàn bộ những trọng số, những kiến thức đã được train trước đó. Đối với mô hình tiếp theo, chúng ta sẽ chuyển sang transfer learning được tinh chỉnh. Điều này có nghĩa là chúng ta sẽ sử dụng cùng một mô hình base_model, nhưng sẽ mở cho một số layer của nó (những lớp gần với output) được có thể train với dữ liệu của chúng ta và chạy mô hình thêm một vài epoch nữa.
model_0.summary()
Model: "model" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_layer (InputLayer) [(None, 224, 224, 3)] 0 _________________________________________________________________ efficientnetb0 (Functional) (None, None, None, 1280) 4049571 _________________________________________________________________ global_avg_pool_2d (GlobalAv (None, 1280) 0 _________________________________________________________________ output (Dense) (None, 10) 12810 ================================================================= Total params: 4,062,381 Trainable params: 12,810 Non-trainable params: 4,049,571 _________________________________________________________________
for layer_index, layer in enumerate(model_0.layers) : print(layer_index, layer.name, layer.trainable)
0 input_layer True 1 efficientnetb0 False 2 global_avg_pool_2d True 3 output True
Tất cả các layer trong layer Effectsnetb0 đã bị đóng băng. Chúng ta có thể xác nhận điều này bằng thuộc tính trainable_variables.
len(model_2.layers[1].trainable_variables)
0
Điều này giống với mô hình cơ sở base_model.
len(base_model.trainable_variables)
0
Thậm chí có thể kiểm tra từng layer trong base_model:
for layer_index, layer in enumerate(base_model.layers) : print(layer_index, layer.name, layer.trainable)
0 input_3 False 1 rescaling_2 False ... 235 top_bn False 236 top_activation False
Bây giờ để tinh chỉnh mô hình cơ sở phù hợp với dữ liệu của, chúng ta sẽ cho phép 10 layer trên cùng được phép train và tiếp tục train mô hình thêm 5 epoch tiếp theo.
Điều này có nghĩa là tất cả các layer của mô hình cơ sở ngoại trừ 10 layer cuối cùng sẽ vẫn bị đóng băng và không thể train được. Và trọng số ở các layer được phép train sẽ được cập nhật trong quá trình train.
🤔 Câu hỏi: Bạn nên mở bao nhiêu lớp khi luyện tập?
Không có quy tắc thiết lập cho điều này. Bạn có thể unfreeze mọi layer trong mô hình được train trước ddos hoặc bạn có thể thử mở từng layer một. Tốt nhất hãy thử với số lượng lượng layer tăng dần dần được tinh chỉnh khác nhau để xem điều gì sẽ xảy ra. Nói chung, neus có càng có ít dữ liệu thì nên dùng ít layer có thể train.
Để bắt đầu tinh chỉnh, trước tiên ta sẽ cho phép tính năng của base_model.trainable là True. Sau đó, tạo vòng lặp cho đến trước phần tử thứ 10 tính từ cuối cùng đi lên và set cho những layer trainable là False. Cụ thể như sau :
base_model.trainable = True for layer in base_model.layers[:-10] : layer.trainable = False
Kiểm tra có bao nhiêu layer có thê train trong trong base_model
for layer_index, layer in enumerate(base_model.layers) : print(layer_index, layer.name, layer.trainable)
0 input_3 False 1 rescaling_2 False 2 normalization_2 False ... 199 block6c_se_reduce False 200 block6c_se_expand False ... 227 block7a_se_squeeze True 228 block7a_se_reshape True 229 block7a_se_reduce True 230 block7a_se_expand True 231 block7a_se_excite True 232 block7a_project_conv True 233 block7a_project_bn True 234 top_conv True 235 top_bn True 236 top_activation True
Có vẻ như tất cả các layer ngoại trừ 10 layer cuối cùng đều bị đóng băng và không thể train được. Điều này có nghĩa là chỉ 10 layer cuối cùng của base_model cùng với output layer sẽ được cập nhật trọng số của chúng trong quá trình train.
🤔 Câu hỏi: Tại sao chúng tôi biên dịch lại mô hình?
Mỗi khi thực hiện thay đổi đối trong mô hình của mình, bạn cần phải biên dịch lại chúng.
Trong trường hợp chúng ta đang sử dụng cùng một hàm loss, trình tối ưu hóa và không gian đo, ngoại trừ lần này learning_rate cho trình tối ưu hóa của chúng ta sẽ nhỏ hơn 10 lần so với trước đây (0,0001 thay vì mặc định của Adam là 0,001).
Chúng ta làm điều này để mô hình không cố gắng ghi đè các trọng số hiện có trong mô hình được đào tạo trước quá nhanh. Nói cách khác, chúng tôi muốn học dần dần.
🔑Lưu ý : Không có tiêu chuẩn thiết lập nào để đặt learning_rate trong quá trình tinh chỉnh, mặc dù mức giảm 2.6x-10x+ dường như hoạt động tốt trong thực tế.
Bây giờ chúng ta có bao nhiêu biến có thể train?
len(model_0.trainable_variables)
2
Chúng tôi sẽ tiếp tục train từ nơi mà mô hình trước đó đã hoàn thành. Vì nó được train trong 5 epochs, quá trình tinh chỉnh của chúng ta sẽ bắt đầu từ epoch thứ 5 và tiếp tục trong 5 với epoch tiếp theo.
fine_tune_epochs = 5 model_0_fine_tune_history = model_0.fit( train_data_10_percent, steps_per_epoch=len(train_data_10_percent), epochs=initial_epochs+fine_tune_epochs, initial_epoch=model_0_history.epoch[-1] + 1, validation_data=test_data, validation_steps=int(0.25 * len(test_data)) )
Epoch 6/10 24/24 [==============================] - 7s 268ms/step - loss: 0.4617 - accuracy: 0.8933 - val_loss: 0.5096 - val_accuracy: 0.8684 ... Epoch 10/10 24/24 [==============================] - 7s 268ms/step - loss: 0.3095 - accuracy: 0.9387 - val_loss: 0.4603 - val_accuracy: 0.8668
🔑 Lưu ý: Quá trình tinh chỉnh thường mất nhiều thời gian hơn trên mỗi epoch so với việc trích xuất đặc tính (do cập nhật nhiều trọng số hơn trong toàn neural).
# Đánh giá mô hình trên dữ liệu test result_fine_tune_10_percent = model_0.evaluate(test_data) result_fine_tune_10_percent
79/79 [==============================] - 11s 133ms/step - loss: 0.4412 - accuracy: 0.8700 [0.44118955731391907, 0.8700000047683716]
Chúng ta sẽ so sánh khả năng học của mô hình giữa 2 giai đoạn trước khi tinh chỉnh (5 epoch đầu) và sau khi tinh chỉnh (5 epoch sau)
def compare_history(original_history, new_history) : og_history = original_history.history n_history = new_history.history og_acc, og_val_acc = og_history["accuracy"], og_history["val_accuracy"] og_loss, og_val_loss = og_history["loss"], og_history["val_loss"] new_acc, new_val_acc = n_history["accuracy"], n_history["val_accuracy"] new_loss, new_val_loss = n_history["loss"], n_history["val_loss"] total_acc = og_acc + new_acc total_val_acc = og_val_acc + new_val_acc total_loss = og_loss + new_loss total_val_loss = og_val_loss + new_val_loss plt.figure(figsize=(20,6)) plt.subplot(121) plt.plot(total_acc,label="train accuracy") plt.plot(total_val_acc, label="val accuracy") plt.plot([model_0_history.epoch[-1],model_0_history.epoch[-1]],plt.ylim(), label="Bắt đầu tinh chỉnh") plt.title("Compare accuracy history") plt.xlabel("epochs") plt.ylabel("percentage") plt.legend() plt.subplot(122) plt.plot(total_loss, label="train loss") plt.plot(total_val_loss, label="val loss") plt.plot([model_0_history.epoch[-1],model_0_history.epoch[-1]],plt.ylim(),label="Bắt đầu tinh chỉnh") plt.title("Compare loss history") plt.xlabel("epochs") plt.ylabel("value") plt.legend()
compare_history(model_0_history, model_0_fine_tune_history)
model_0 có đã cải thiện đáng kể sau khi chúng ta cho phép một số layer trong base_model được phép train trên dữ liệu này.
Tương tự, chúng ta sẽ áp dụng 10% dữ liệu train này vào model_2 nhưng các dữ liệu này khi đưa vào mô hình sẽ có một layer sau đó sẽ thực hiện công việc "biến dạng" làm cho dữ liệu thay đổi đa dạng hơn.
5.4. Model 2 tinh chỉnh : Xây dựng mô hình transfer learning được tinh chỉnh trên 10% dữ liệu train tăng cường tính đa dạng.
from tensorflow.keras.utils import plot_model
plot_model(model_2)
Chúng ta sẽ tận dụng lại model_2 để thực hiện transfer learning tinh chỉnh
fine_tune_epoch=5 model_2.compile( loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"] ) model_2_fine_tune_history = model_2.fit( train_data_10_percent, steps_per_epoch=len(train_data_10_percent), epochs=initial_epochs + fine_tune_epochs, initial_epoch=model_2_history.epoch[-1] + 1, validation_data=test_data, validation_steps=int(0.25 * len(test_data)) )
Epoch 6/10 24/24 [==============================] - 24s 699ms/step - loss: 0.7477 - accuracy: 0.7693 - val_loss: 0.6167 - val_accuracy: 0.7928 ... Epoch 10/10 24/24 [==============================] - 14s 597ms/step - loss: 0.1624 - accuracy: 0.9560 - val_loss: 0.4702 - val_accuracy: 0.8487
Đánh giá model_2 sau khi được tinh chỉnh
results_fine_tune_10_percent_data_aug = model_2.evaluate(test_data) results_fine_tune_10_percent_data_aug
79/79 [==============================] - 11s 132ms/step - loss: 0.4351 - accuracy: 0.8616 [0.4350980818271637, 0.8615999817848206]
Trong quá trình train, chúng ta chỉ sử dụng 25% dữ liệu test để đánh giá sau mỗi epoch. Khi đánh giá toàn bộ dữ liệu, có thể thấy tỉ lệ chính xác cao hơn.
So sánh khả năng học của mô hình giữa 2 giai đoạn trước khi tinh chỉnh và sau khi tinh chỉnh
compare_history(model_2_history, model_2_fine_tune_history)
OK, với mô hình sau khi được tinh chỉnh, có vẻ nó cũng đã được cải thiện đáng kể.
5.5. Model 2 : Xây dựng mô hình transfer learning được tinh chỉnh trên toàn bộ dữ liệu train được tăng tính đa dạng
Chúng ta đã xây dựng mô hình và thử nghiệm với những dữ liệu nhỏ. Có thể thấy khả năng học của mô hình là rất tốt. Bây giờ, chúng ta sẽ đưa toàn bộ dữ liệu vào để có thể có sự đánh giá tốt nhất đối với mô hình học.
Trước hết chúng ta sẽ tải dữ liệu và khai thác các cấu trúc nằm trong tập dữ liệu đó có gì.
!wget https://www.dropbox.com/s/xjyf4ug18zqvig0/10_food_classes.zip
10_food_classes.zip 100%[===================>] 478.05M 60.2MB/s in 7.7s 2021-09-10 02:44:54 (61.7 MB/s) - ‘10_food_classes.zip’ saved [501269035/501269035]
unzip_file("10_food_classes.zip")
Unzipped file
walk_through_directory("10_food_classes")
Có 2 thư mục và 0 tập tin trong thư mục 10_food_classes Có 10 thư mục và 0 tập tin trong thư mục 10_food_classes/test Có 0 thư mục và 250 tập tin trong thư mục 10_food_classes/test/greek_salad ... Có 0 thư mục và 750 tập tin trong thư mục 10_food_classes/train/clam_chowder
Trong tập dữ liệu 10_food_classes có tổng cộng 10 class, mỗi class gồm 750 hình ảnh để train, 250 hình ảnh để test.
Tạo đường dẫn đến tập dữ liệu 10 class đầy đủ
train_10_class_full_data_dir = "10_food_classes/train" test_10_class_full_data_dir = "10_food_classes/test"
Chúng ta sẽ biến các hình ảnh thành bộ dữ liệu tensors.
IMAGE_SHAPE = (224,224) train_full_data = image_dataset_from_directory( train_10_class_full_data_dir, label_mode="categorical", image_size=IMAGE_SHAPE ) test_data = image_dataset_from_directory( test_10_class_full_data_dir, label_mode="categorical", image_size=IMAGE_SHAPE )
Found 7500 files belonging to 10 classes. Found 2500 files belonging to 10 classes.
Như hiện tại, model_2 của chúng ta đã được tinh chỉnh trên 10% dữ liệu, vì vậy để bắt đầu tinh chỉnh tất cả dữ liệu và giữ cho các thử nghiệm được nhất quán, chúng ta cần load nó về các trọng số mà chúng tôi đã kiểm tra sau 5 epoch mô hình trích xuất đặc tính.
Tận dụng CheckPoint callback đã được thực hiện trong model_2 để load lại trọng số và đặc tính trong 5 epoch đầu tiên.
model_2.load_weights("checkpoints/model_2_10_percent_data_aug.ckpt")
<tensorflow.python.training.tracking.util.CheckpointLoadStatus at 0x7f0ad9accf10>
loaded_results_10_percent_data_aug = model_2.evaluate(test_data) loaded_results_10_percent_data_aug
79/79 [==============================] - 11s 132ms/step - loss: 0.6307 - accuracy: 0.8252 [0.6307364106178284, 0.8252000212669373]
So sánh với kết quả đánh giá model_2 của 5 epoch đầu tiên xem có khớp hay không
result_10_percent_data_aug
[0.6307364106178284, 0.8252000212669373]
loaded_results_10_percent_data_aug == result_10_percent_data_aug
True
Kiểm tra xem một số layer cuối cùng của mô hình cơ sở base_model đã cho phép train với dữ liệu mới hay chưa.
for layer_index, layer in enumerate(model_2.layers) : print(layer_index, layer.name, layer.trainable)
0 input_layer True 1 data_augmentation True 2 efficientnetb0 True 3 global_average_pooling2d_1 True 4 outputs True
for layer_index, layer in enumerate(model_2.layers[2].layers) : if layer.trainable: print(layer_index, layer.name, layer.trainable)
227 block7a_se_squeeze True 228 block7a_se_reshape True ... 235 top_bn True 236 top_activation True
Như vậy mô hình model_2 đã được load lại lúc chưa tinh chỉnh. Bây giờ, chúng ta sẽ bắt đầu tinh chỉnh mô hình với full dữ liệu. Nhớ là bạn muốn thay đổi tham số nào đó trong mô hình, bạn phải compile nó lại.
model_2.compile( loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"] ) model_2_fine_tune_all_data_history = model_2.fit( train_full_data, steps_per_epoch=len(train_full_data), epochs=initial_epochs+fine_tune_epoch, initial_epoch= model_1_history.epoch[-1] + 1, validation_data=test_data, validation_steps=int(0.25 * len(test_data)) )
Epoch 6/10 235/235 [==============================] - 78s 296ms/step - loss: 0.6094 - accuracy: 0.7960 - val_loss: 0.3654 - val_accuracy: 0.8849 ... Epoch 10/10 235/235 [==============================] - 73s 307ms/step - loss: 0.2904 - accuracy: 0.9031 - val_loss: 0.2634 - val_accuracy: 0.9161
Đánh giá mô hình được tỉnh chỉnh với dữ liệu đầy đủ .
results_fine_tune_full_data = model_2.evaluate(test_data) results_fine_tune_full_data
79/79 [==============================] - 11s 132ms/step - loss: 0.2433 - accuracy: 0.9184 [0.2433045655488968, 0.91839998960495]
Có vẻ như việc tinh chỉnh tất cả dữ liệu được tăng tính đa dạng đã giúp cho mô hình của chúng có được kết quả rất tốt.
Check learning curves của mô hình
plot_loss_curves(model_2_fine_tune_all_data_history)
So sánh mức độ hiệu quả của mô hình qua 2 giai đoạn, trước khi tinh chỉnh mô hình với 10% dữ liệu train, và giai đoạn tinh chỉnh với đầy đủ dữ liệu train, và tất cả dữ liệu đều được tăng cường tính đa dạng.
compare_history(model_2_history,model_2_fine_tune_all_data_history)
6. So sánh kết quả thử nghiệm mô các mô hình hình bằng TensorBoard
Kết quả thử nghiệm các mô hình đã được lưu lại trong tensornoard. Nếu chúng ta muốn chia sẻ chúng với ai đó, họ sẽ nhận được biểu đồ và các số liệu đánh giá từ các mô hình.
🔑 Lưu ý: Nhớ rằng mọi thứ bạn upload lên
TensorBoard.devđều được công khai. Nếu có những thông tin nhạy, vui lòng cảm đừng tải lên.
!tensorboard dev upload --logdir transfer_learning_fine_tuning \ --name "Transfer learning experiments" \ --description "A series of different transfer learning experiments with varying amounts of data and fine-tuning" \ --one_shot
Khi chúng ta đã upload các kết quả lên TensorBoard.dev, chúng ta sẽ nhận được một liên kết có thể chia sẻ mà chúng ta có thể sử dụng để xem và so sánh các thử nghiệm của mình và chia sẻ những kết quả đó với những người khác nếu cần.
Để tìm tất cả các thử nghiệm TensorBoard.dev bạn có thể gõ lệnh để hiển thị danh sách các thử nghiệm đã diễn ra :
!tensorboard dev list
tensorboard dev delete --experiment_id [Id của thử nghiệm]
!tensorboard dev delete --experiment_id y0VMGHgcRZWTl8vmFririg
Deleted experiment y0VMGHgcRZWTl8vmFririg.
Kiểm tra lại danh sách xem thử nghiệm với Id y0VMGHgcRZWTl8vmFririg đã được xóa chưa
!tensorboard dev list