Deep Learning với Tensorflow Module 6 phần 3: Transfer learning Mở rộng dữ liệu
Trong 2 phần trước ( phần 1 :transfer learning trích xuất đặc trưng và phần 2 : transfer learning được tinh chỉnh), chúng ta đã thấy được sức mạnh của những mô hình đã được train trước đó. Mặc dù những mô hình trước mà chúng ta làm là những mô hình sử dụng dữ liệu tương đối nhỏ (ít dữ liệu, ít class). Trong phần này, chúng ta sẽ sử dụng lượng dữ liệu lớn hơn.
Trong Machine learning cũng như Deep learning, trước khi chính thức sử dụng một mô hình nào đó, chúng ta cần thử nghiệm khả năng học của nó. Một mô hình tốt là mô hình có khả năng học được trên cả lượng dữ liệu nhỏ đến lượng dữ liệu lớn. Do đó, khi xây dựng mô hình, chúng ta sẽ bắt đầu từ dữ liệu nhỏ, rồi sau đó dần dần mở rộng trên tập dữ liệu lớn hơn.
Trong phần này, chúng ta sẽ mở rộng phạm vi dữ liệu từ việc sử dụng 10 class sang việc sử dụng tất cả các class trong tập dữ liệu Food101.
Mục tiêu của chúng ta là đánh bại kết quả của Food101 paper với 10% dữ liệu.
Nội dụng trong phần này :
- Download và chuẩn bị 10% dữ liệu cho 101 class trong Food101
- Xây dựng mô hình Transfer learning trích xuất đặc trưng
- Tinh chỉnh mô hình trích xuất đặc trưng
- Lưu và Load mô hình
- Đánh giá hiệu suất mô hình
- Dự đoán hình ảnh lấy từ dữ liệu test
- Sử dụng các phương pháp đánh giá từ sklearn
- Sử dụng pandas để Tìm top các dự đoán sai trong mô hình.
1. Download và chuẩn bị 10% dữ liệu cho 101 class trong Food101
Trong tập dữ liệu gốc của Food101, có 1000 hình ảnh cho mỗi class (750 hình ảnh để train và 250 hình ảnh để test), tổng cộng 101.000 hình ảnh.
Trước khi toàn bộ hình ảnh của tập dữ liệu train trên 101 class, chúng ta sẽ thử nghiệm với 10% dữ liệu train của nó.
!wget https://www.dropbox.com/s/8pakapzwodimtvw/all_food_classes_10_percent.zip
Như thường lệ, trước khi xây dựng mô hình, chúng ta cần phải hiểu dữ liệu hiện tại là gì, cấu trúc của dữ liệu gồm những gì, nó đã được chia thành 2 phần train và test hay chưa... Do đó, chúng ta sẽ dạo quanh tập dữ liệu vừa mới tải xuống. Để toàn bộ code trong notebook được gọn gàng, chúng ta có thể viết những hàm có thể tái sử dụng nhiều lần trong file khác rồi sau đó import các hàm trong file đó. Với bài viết này sẽ import utility function này trên cloud.
!wget https://www.dropbox.com/s/v4sla7jvi9cltg8/utility_functions.py
from utility_functions import walk_through_directory, unzip_file, plot_loss_curves,create_tensorboard_callback, compare_history , plot_confusion_matrix
Giải nén tập tin "all_food_classes_10_percent.zip"
unzip_file("/content/all_food_classes_10_percent.zip")
Unzipped file
walk_through_directory("/content/all_food_classes_10_percent")
Có 2 thư mục và 0 tập tin trong thư mục /content/all_food_classes_10_percent Có 101 thư mục và 0 tập tin trong thư mục /content/all_food_classes_10_percent/train ... Có 0 thư mục và 250 tập tin trong thư mục /content/all_food_classes_10_percent/test/beef_carpaccio Có 0 thư mục và 250 tập tin trong thư mục /content/all_food_classes_10_percent/test/panna_cotta
Sử dụng hàm image_dataset_from_directory() để chuyển dữ liệu hình ảnh và label của nó vào tf.data.Dataset, một kiểu dữ liệu TensorFlow cho phép chúng ta chuyển thư mục của nó vào mô hình.
Đối với tập dữ liệu test, chúng ta sẽ đặt shuffle = False để những dữ liệu này được đưa vào đúng theo trình tự, đồng thời giúp cho chúng ta có thể dễ dàng đánh giá và quan sát đúng vị trí hình hiện tại trong tập dữ liệu đó.
import tensorflow as tf
train_dir = "all_food_classes_10_percent/train" test_dir = "all_food_classes_10_percent/test"
IMAGE_SHAPE=(224,224) train_data_10_percent = tf.keras.preprocessing.image_dataset_from_directory( train_dir, label_mode="categorical", image_size=IMAGE_SHAPE, shuffle=True, ) test_data = tf.keras.preprocessing.image_dataset_from_directory( test_dir, label_mode="categorical", image_size=IMAGE_SHAPE, shuffle=False )
Found 7575 files belonging to 101 classes. Found 25250 files belonging to 101 classes.
Với việc sử dụng tf.data.Dataset API, chúng ta có thể lấy được tên của các class với thuộc tính class_names
class_names = train_data_10_percent.class_names print(class_names)
['apple_pie', 'baby_back_ribs', 'baklava', ..., 'steak', 'strawberry_shortcake', 'sushi', 'tacos', 'takoyaki', 'tiramisu', 'tuna_tartare', 'waffles']
Dữ liệu của chúng ta đã được import như kỳ vọng, 75 hình ảnh / class, có 101 class nên 75 x 101 = 7575 hình ảnh để train. Và 250 hình ảnh test / class, nên có 250 * 101 = 25250 class.
Dữ liệu hình ảnh về 101 food của chúng ta đã được import vào TensorFlow, tiếp theo sẽ là lập mô hình.
2. Xây dựng mô hình Transfer learning trích xuất đặc trưng
Để thử nghiệm nhanh chóng với lượng dữ liệu hiện tại, chúng ta sẽ bắt đầu bằng mô hình transfer learning trích xuất đặc trưng, mô hình này chúng ta sẽ sử dụng toàn bộ các đặc trưng mà mô hình đã được train trước đó trong 5 epoch đầu tiên. Sau đó, ta sẽ cải thiện mô hình bằng cách tinh chỉnh một vài layer và train thêm 5 epoch nữa.
Cụ thể hơn, mục tiêu của chúng ta sẽ là xây dựng mô hình có thể vượt qua đường cơ sở tại Food101 paper(độ chính xác 50,76% trên 101 lớp) với 10% dữ liệu train. Và các bước thiết lập mô hình như sau :
+ Tạo hàm ModelCheckPoint Callback để lưu quá trình train của mô hình trong 5 epoch đầu tiên. Điều này giúp chúng ta sau này có thể train mô hình tiếp tục mà không cần phải train lại từ đầu.
+ Tạo input layer truyền vào kích thước hình ảnh
+ Làm dữ liệu được tăng tính đa dạng (data augmentation) được tích hợp thành 1 layer trong mô hình.
+ Sử dụng mô hình transfer learning làm mô hình cơ sở với kiến trúc EfficientNetB0
+ Tạo 1 output layer là Dense layer với unit neuron là 101 (có thể hiểu layer này sẽ tính toán xác suất có thể xảy ra với số class tương ứng) và sử dụng hàm activation là softmax (đại diên cho mô hình phân loại)+ Tạo mô hình, đưa các inputs, và output vào mô hình
+ Biên dịch mô hình (compile) bao gồm :
+ hàm loss : categorical_crossentropy
+ trình tối ưu cho mô hình : Adam
+ Không gian đo khả năng học của mô hình accuracy
+ Fit mô hình với 5 epoch với train_data là dữ liệu được dùng để train, test_data là dữ liệu để kiểm định sau mỗi khi quá trình train kết thúc.
Để bắt đầu, chúng ta sẽ tạo hàm để gọi ModelCheckPoint callback :
import os def create_checkpoint_model_callback(dir_name, experiment_name) : checkpoint_path = os.path.join(dir_name, experiment_name + ".ckpt") checkpoint_model_cb = tf.keras.callbacks.ModelCheckpoint(checkpoint_path, monitor="val_loss", verbose=1, save_best_only=False, save_weights_only=True) print(f"Đã lưu checkpoint model callback vào {checkpoint_path}") return checkpoint_model_cb
from tensorflow.keras import Sequential, Model, layers from tensorflow.keras.layers.experimental import preprocessing
Chúng ta sẽ tạo sẵn mộ mô hình giúp biến dữ liệu trở nên đa dạng (data augmentation) và sau đó chèn mô hình này như một layer vào mô hình Functional API.
Functional API là lúc chúng ta kết hợp các layer với mô hình transfer learning trích xuất đặc trưng (trong trường hợp này là EfficientB0 được sử dụng như mô hình cơ sở.
data_augmentation = Sequential([ preprocessing.RandomFlip("horizontal"), preprocessing.RandomZoom(0.2), preprocessing.RandomWidth(0.2), preprocessing.RandomHeight(0.2), preprocessing.RandomRotation(0.25), preprocessing.RandomZoom(0.2), # preprocessing.Rescaling(1./255) # giữ lại nếu là mô hình như ResNet50V2, không sử dụng cho EfficientNet ])
Mô hình cơ sở của chúng ta sẽ giữ nguyên các trích xuất đặc trưng, sử dụng include_top=False để thay đổi số class output mặc định của mô hình này là 1000 thành số class phù hợp với dữ liệu của chúng ta (101 class). Lưu ý, GlobalAveragePooling2D() giúp cô đọng các output của mô hình cơ sở thành hình dạng phù hợp với hình dạng có thể dùng cho output layer được định nghĩa bởi Dense layer tiếp nối.
base_model = tf.keras.applications.EfficientNetB0(include_top = False) # Set trainable là False để các layer trong base_model được giữ nguyên các trọng số (weights) và bias base_model.trainable=False
Downloading data from https://storage.googleapis.com/keras-applications/efficientnetb0_notop.h5 16711680/16705208 [==============================] - 0s 0us/step 16719872/16705208 [==============================] - 0s 0us/step
# Định nghĩa inputs cho mô hình (hình dạng của dữ liệu) inputs = layers.Input(shape=IMAGE_SHAPE+(3,), name="inputs_layer") # Định nghĩa layer làm dữ liệu bị 'biến dạng' inputs_augmetation = data_augmentation(inputs) # Chèn layer trên vào base_model x = base_model(inputs_augmetation, training=False) # Sử dụng GlobalAveragePooling2D để gộp các output của base_model trên x = layers.GlobalAveragePooling2D()(x) # Tạo output bằng Dense layer với units neuron chính là số class của dữ liệu, và activation là softmax outputs = layers.Dense(len(class_names), activation="softmax")(x) model_0 = Model(inputs, outputs, name="model_0")
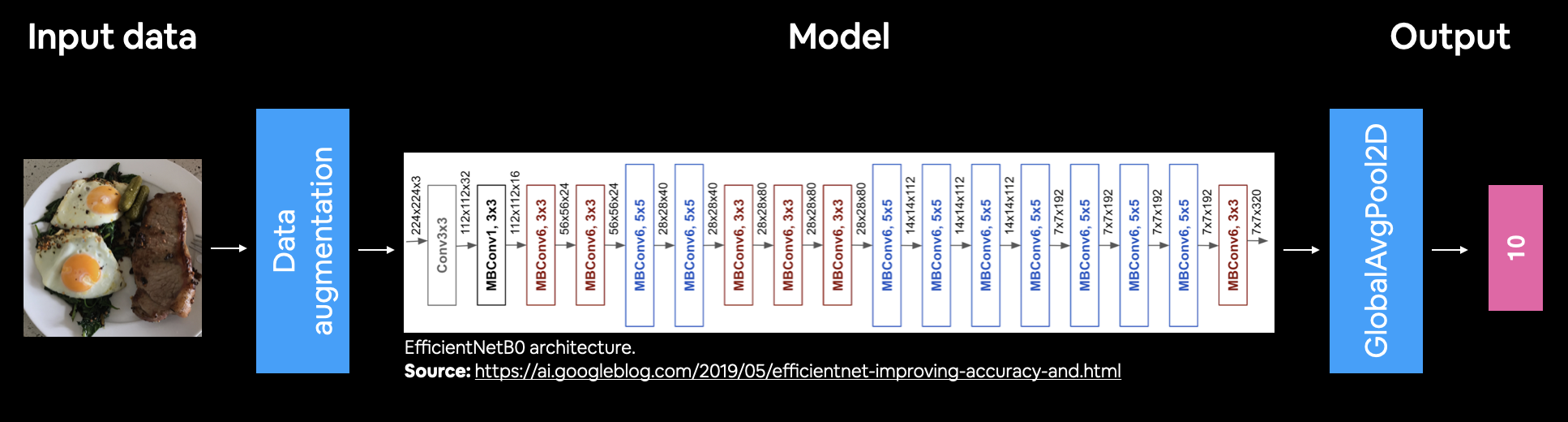
GlobalAveragePooling2D và Dense với 10 unit neurons dưới dạng output.Tổng quan mô hình
model_0.summary()
Model: "model_0" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= inputs_layer (InputLayer) [(None, 224, 224, 3)] 0 _________________________________________________________________ sequential (Sequential) (None, None, None, 3) 0 _________________________________________________________________ efficientnetb0 (Functional) (None, None, None, 1280) 4049571 _________________________________________________________________ global_average_pooling2d (Gl (None, 1280) 0 _________________________________________________________________ dense (Dense) (None, 101) 129381 ================================================================= Total params: 4,178,952 Trainable params: 129,381 Non-trainable params: 4,049,571 _________________________________________________________________
Mô hình Functional API chúng ta có 5 layer, nhưng trong mỗi layer lại chứa những layer khác để tạo nên nó. VD, efficientnetb0 (Functional) có 238 layer chứa trong nó.
Tiếp theo chúng ta sẽ biên dịch mô hình và bắt đầu train mô hình bằng phương thức fit
# Tạo số epoch để thực hiện transfer learning trích xuất đặc trưng initial_epoch=5 # Biên dịch mô hình (compile): model_0.compile( loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"] ) # Fit mô hình model_0_feature_extraction_history = model_0.fit( train_data_10_percent, steps_per_epoch=len(train_data_10_percent), epochs=initial_epoch, validation_data=test_data, validation_steps=int(0.25 * len(test_data)), callbacks=[ create_tensorboard_callback("transfer_learning", "efficientB0_extract_feature_101_class_10_percent_data"), create_checkpoint_model_callback("model_checkpoints", "model_0_feature_extraction") ] )
Đã lưu tensorboard vào transfer_learning/efficientB0_extract_feature_101_class_10_percent_data/13092021-095346 Đã lưu checkpoint model callback vào model_checkpoints/model_0_feature_extraction.ckpt Epoch 1/5 237/237 [==============================] - 164s 552ms/step - loss: 3.5476 - accuracy: 0.2330 - val_loss: 2.6884 - val_accuracy: 0.3969 Epoch 00001: saving model to model_checkpoints/model_0_feature_extraction.ckpt ... Epoch 00004: saving model to model_checkpoints/model_0_feature_extraction.ckpt Epoch 5/5 237/237 [==============================] - 87s 367ms/step - loss: 1.7816 - accuracy: 0.5706 - val_loss: 1.9164 - val_accuracy: 0.5117 Epoch 00005: saving model to model_checkpoints/model_0_feature_extraction.ckpt
results_model_0_feature_extraction = model_0.evaluate(test_data) results_model_0_feature_extraction
790/790 [==============================] - 102s 128ms/step - loss: 1.7848 - accuracy: 0.5410 [1.7848315238952637, 0.5409504771232605]
accuracy của mô hình đạt ~53% vượt qua độ chính xác cơ sở trong Food101 paper chỉ với 10% dữ liệu. 😂
Vậy learning curves của mô hình sẽ như thế nào ?
plot_loss_curves(model_0_feature_extraction_history)
🤔 Tại sao chúng ta lại vẽ đường learning curves? Về cơ bản, chúng ta sẽ đánh giá quá trình học của mô hình và quá trình tự đánh giá lại sau mỗi lần nó học xong, để xác định xác liệu mô hình có bị
overfittinghayunderfittinghay không.
3. Tinh chỉnh mô hình trích xuất đặc trưng
Mô hình trích xuất đặc trưng đã thực hiện khá tốt với 101 class. Nhưng để mô hình có thể học tốt hơn, chúng ta sẽ mở một số layer trong base_model được phép train lại trên dữ liệu của chúng ta.
Nhờ model_0 vừa rồi chúng ta có sử dụng ModelCheckpoint callback để lưu lại toàn bộ các trọng số của mô hình với 5 epoch, nên shúng ta sẽ thực hiện tinh chỉnh mô hình với 5 epoch tiếp theo, nếu mô hình train tốt, chúng ta sẽ giữ lại mô hình mới, còn nếu không tốt chúng ta sẽ load lại 5 epoch của mô hình trích xuất đặc trưng như phần trên mà không cần phải train lại từ đầu.
Để tinh chỉnh mô hình base_model, chúng ta sẽ set lại trainable của base_model thành True. Khi dữ liệu càng lớn, số layer cho phép train lai càng nhiều sẽ càng tốt, nhưng chúng ta chỉ sử dụng 10% dữ liệu cho mọi class, nên chúng ta sẽ chỉ cho phép một vài layer trên cùng được train lại, phần lại vẫn giữ nguyên.
Cụ thể, sử dụng 5% layer trên cùng được phép train lại, 90% vẫn giữ nguyên.
Đầu tiên chúng ta sẽ xác định 5% layer cuối bắt đầu từ đâu
get_total_base_model_layers = len(base_model.layers) last_ten_percent_of_total_number_layers = int(0.95 * get_total_base_model_layers ) last_ten_percent_of_total_number_layers
225
Vậy 5% layer cuối cùng bắt đầu từ layer thứ 225.
- Set
base_model.trainable = False - Tạo vòng lặp để cho phép layer thứ 213 trở về sau được train
base_model.trainable = False for layer in base_model.layers[last_ten_percent_of_total_number_layers:] : layer.trainable = True
Kiểm tra lại xem trong base_model đã cho phép train một số layer trên cùng hay chưa.
for layer_index, layer in enumerate(base_model.layers) : if layer.trainable : print(layer_index, layer.name)
225 block7a_bn 226 block7a_activation 227 block7a_se_squeeze 228 block7a_se_reshape 229 block7a_se_reduce 230 block7a_se_expand 231 block7a_se_excite 232 block7a_project_conv 233 block7a_project_bn 234 top_conv 235 top_bn 236 top_activation
Bởi vì đang tinh chỉnh, nên chúng ta sẽ sử dụng learning_rate thấp hơn 10 lần để đảm bảo các quá trình cập nhật lại các trong số đã được train trước đó không quá lớn.
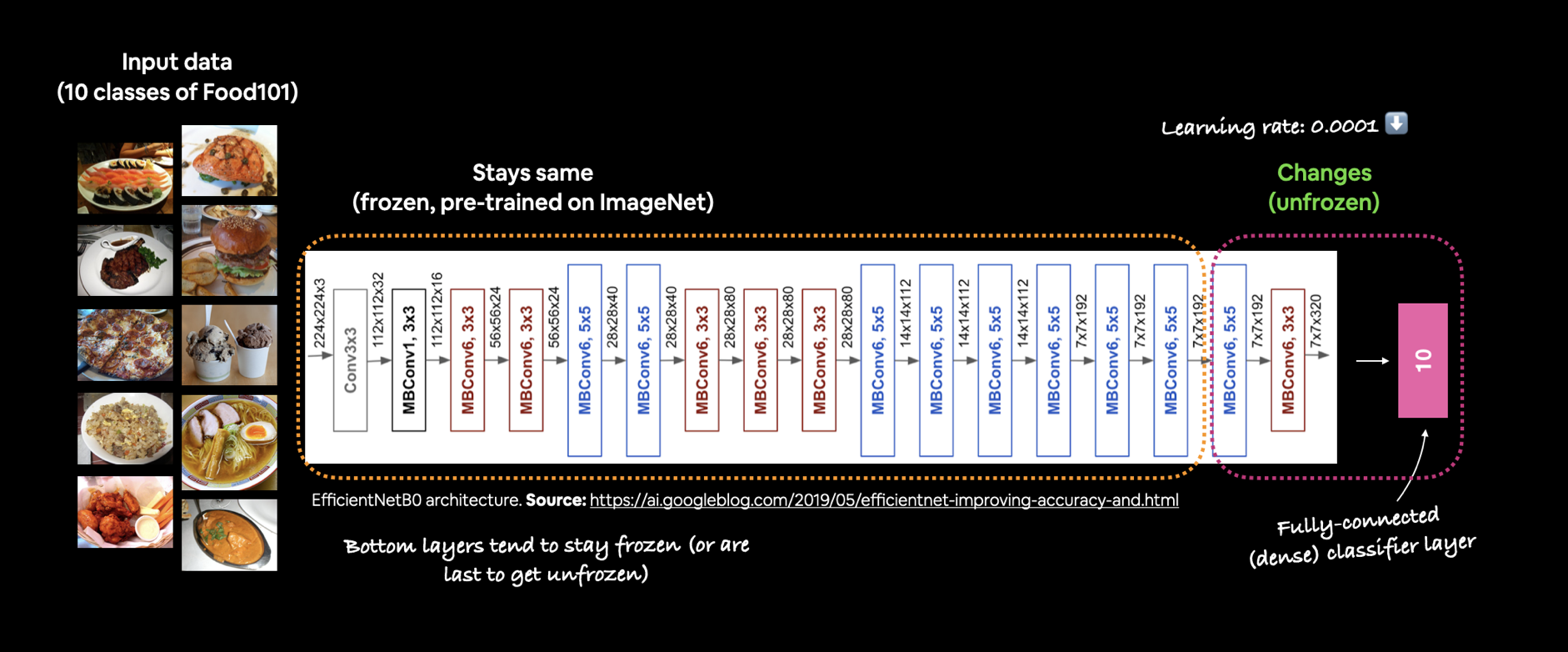
model_0.compile( loss="categorical_crossentropy", optimizer=tf.keras.optimizers.Adam(learning_rate=0.0001), # mặc định là 0.001, ta sẽ giảm 10 lần giá trị mặc định metrics=["accuracy"] )
Mô hình model_0 đã được compile lại, chúng ta sẽ thiếp lập cho mô hình này train tiếp tục thêm 5 epoch nữa.
fine_tune_epoch = initial_epoch + 5 model_0_fine_tune_history = model_0.fit( train_data_10_percent, steps_per_epoch = len(train_data_10_percent), epochs=fine_tune_epoch, initial_epoch=model_0_feature_extraction_history.epoch[-1], validation_data=test_data, validation_steps=int(0.25 * len(test_data)), callbacks=[ create_tensorboard_callback("transfer_learning", "efficientB0_fine_tune_101_class_10_percent_data") ] )
Đã lưu tensorboard vào transfer_learning/efficientB0_fine_tune_101_class_10_percent_data/13092021-100618 Epoch 5/10 237/237 [==============================] - 95s 371ms/step - loss: 1.6571 - accuracy: 0.6059 - val_loss: 1.9191 - val_accuracy: 0.5076 ... Epoch 10/10 237/237 [==============================] - 89s 373ms/step - loss: 1.5559 - accuracy: 0.6239 - val_loss: 1.9009 - val_accuracy: 0.5149
result_model_0_fine_tune = model_0.evaluate(test_data)
790/790 [==============================] - 101s 128ms/step - loss: 1.7402 - accuracy: 0.5516
Kiểm tra quá trình học của mô hình qua learning curves:
plot_loss_curves(model_0_fine_tune_history)
Khả năng học của mô hình qua 2 giai đoạn qua biểu đồ:
compare_history(model_0_feature_extraction_history, model_0_fine_tune_history)
Qua biểu đồ trên có thể thấy trước giai đoạn tinh chỉnh, mô hình có khả năng học tốt hơn qua từng epoch. Nhưng đến giai đoạn tinh chỉnh, mặc dù khi train, mô hình học rất tốt, nhưng khi kiểm định lại nó không cho thấy sự tiến bộ nào. Điều này cho thấy mô hình đang bị overfitting.
Trong trường hợp của chúng ta, mô hình EfficientNetB0 đã được train trước đó trên ImageNet có chứa nhiều hình ảnh thực tế về food giống như tập dữ liệu của chúng ta. Nếu trích xuất đặc trưng đã làm rất tốt, thì việc tinh chỉnh mô hình, khiến cho các layer có thể train lại trên dữ liệu của chúng ta sẽ khiến các trọng số trước đó không còn được giữ nguyên mà nó thay đổi dựa trên dữ liệu của chúng ta và với lượng dữ liệu quá ít khiến cho việc train các layer này không còn được tốt nữa.
5. Lưu và load mô hình
Để không phải mất thời gian train lại mô hình, chúng ta sẽ lưu mô hình trên lại bằng phương thức save. Trong bài viết này, chúng ta sẽ lưu trên Google Drive, đầu tiên, bạn cần kết nối đến Driver với lệnh sau :
Lưu mô hình
from google.colab import drive drive.mount('/content/drive')
model_0.save("drive/MyDrive/tensorflow/transfer_learning/transfer_learning_scalling_up_model_0")
Sau đó, bạn có thể tải folder vừa lưu về máy, nén thành một file zip và upload lên cloud.
Load mô hình
Giả sử mô hình đã được lưu, nén lại và tải về máy, bạn sẽ upload nó lên một cloud nào đó của Dropbox hoặc từ Amazone... Sau đó, sử dụng lệnh sau để download xuống
saved_model_path = "/content/drive/MyDrive/tensorflow/transfer_learning/transfer_learning_scalling_up_model_0"
loaded_model = tf.keras.models.load_model(saved_model_path)
Kiểm tra xem mô hình loaded_model có giống như mô hình được save lại hay không (model_0) bằng cách đưa dữ liệu test để đánh giá loaded_model:
results_loaded_model = loaded_model.evaluate(test_data) results_loaded_model
790/790 [==============================] - 105s 130ms/step - loss: 1.7402 - accuracy: 0.5516 [1.7402280569076538, 0.5516435503959656]
Xem lại kết quả đánh giá của model_0 ở trên:
result_model_0_fine_tune
[1.7402280569076538, 0.5516435503959656]
So sánh :
result_model_0_fine_tune == results_loaded_model
True
6. Đánh giá hiệu suất mô hình
🔑 Lưu ý: Đánh giá một mô hình trong học máy cũng quan trọng như việc train một mô hình. Khi tiến hành đánh giá, chúng ta không đưa những dữ liệu mà mô hình đã train vào, mà cần đưa những dữ liệu nó chưa từng biết đến để có thể đánh giá được đúng đắn hiệu suất của mô hình.
Dự đoán hình ảnh lấy từ dữ liệu test
Để đánh giá mô hình được train của, chúng ta cần đưa ra một số dự đoán với nó và sau đó so sánh những dự đoán đó với tập dữ liệu test.
Bởi vì mô hình chưa bao giờ nhìn thấy tập dữ liệu thử nghiệm, điều này sẽ cung cấp cho chúng ta dấu hiệu về cách mô hình sẽ hoạt động trong thế giới thực trên dữ liệu tương tự như những gì nó đã được train.
Để đưa ra các dự đoán với mô hình được train của, chúng tôi có đưa dữ liệu test vào trong phương thức predict().
Vì dữ liệu của chúng ta có nhiều class, giá trị dự đoán sẽ là một mảng với số phần tử trong mảng tương ứng với số class. Mỗi phần tử thể hiện xác suất xảy ra của class đó, tổng các giá trị của tất cả phần tử là ~1.
Nói cách khác, mỗi khi mô hình được train khi nhìn thấy một hình ảnh nào đó, nó sẽ so sánh nó với tất cả các mẫu mà nó đã học được trong quá trình train và trả về output (tất cả 101 class) cho thấy khả năng có thể xảy ra hình ảnh đó thuộc class nào.
pred_probs = model_0.predict(test_data,verbose=1) pred_probs[:5]
790/790 [==============================] - 88s 110ms/step
array([[2.97716856e-01, 2.63235136e-03, 2.80539930e-01, 3.19867795e-05, 1.44368198e-04, 4.95789063e-05, 7.35873415e-04, 1.02811326e-04, ... 2.28483943e-04, 1.11915090e-03, 2.96756276e-03, 1.17756845e-03, 8.16503947e-04]], dtype=float32)
pred_probs.shape
(25250, 101)
Có 25250 hình ảnh, và mỗi hình ảnh là một mảng gồm 101 phần tử đại diện cho 101 class, trong đó giá trị của mỗi phần tử là xác suất xảy ra cho class đó.
VD với hình ảnh đầu tiên :
print(f"Số phần tử được dự đoán cho hình ảnh đầu tiên : {len(pred_probs[0])}") print(f"Xác suất xảy ra của 101 class: {pred_probs[0]}") print(f"Class có giá trị dự đoán cao nhất : {pred_probs[0].max()} tại vị trí {pred_probs[0].argmax()}")
Số phần tử được dự đoán cho hình ảnh đầu tiên : 101 Xác suất xảy ra của 101 class: [2.97716856e-01 2.63235136e-03 2.80539930e-01 3.19867795e-05 ... 1.05346995e-03 4.32252930e-03] Class có giá trị dự đoán cao nhất : 0.2977168560028076 tại vị trí 0
Tiếp theo, chúng ta sẽ dự đoán label của mỗi class dựa trên vị trí chứa giá trị xác suất cao nhất.
import numpy as np
y_pred_labels = np.argmax(pred_probs,axis=1) y_pred_labels[:10]
array([ 0, 0, 7, 0, 0, 78, 29, 46, 2, 41])
Chúng ta sẽ có thể so sánh các label này với các label trên tập dữ liệu test để đánh giá thêm mô hình.
Vì dữ liệu test hiện không phải là dữ liệu tuần tự mà nó đã được chia theo cụm với mỗi cụm là 32 hình ảnh. Vì vậy, vì vậy chúng ta không thể so sánh được. Trước hết, chúng ta sẽ phân giải cụm này trở về với hình ảnh tuần tự bằng phương thức unbatch()
y_labels = [] for image, label in test_data.unbatch() : y_labels.append(tf.argmax(label).numpy()) y_labels[:10]
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
Sử dụng các phương pháp đánh giá từ sklearn
Một đánh giá rất đơn giản là sử dụng hàm accuracy_score() của Scikit-Learn để so sánh các label thật với các label được dự đoán và trả về xác suất chính xác
from sklearn.metrics import accuracy_score sklearn_accuracy = accuracy_score(y_pred_labels, y_labels) sklearn_accuracy
0.5516435643564357
So sánh với giá trị đánh giá từ mô hình
np.isclose(sklearn_accuracy, result_model_0_fine_tune[1]) # Vì trong result_model_0_fine_tune là list [loss, accuracy]
True
Để đánh giá chi tiết xác suất dự đoán của từng class, chúng ta sẽ tạo confusion_matrix() để có thể thấy rõ tỉ lệ dự đoán cụ thể giữa các label
from sklearn.metrics import confusion_matrix
confusion_matrix(y_labels, y_pred_labels)
array([[ 62, 0, 9, ..., 3, 0, 12], [ 0, 192, 0, ..., 0, 0, 0], [ 26, 5, 132, ..., 1, 0, 1], ..., [ 8, 0, 4, ..., 67, 0, 4], [ 0, 2, 0, ..., 0, 43, 0], [ 4, 0, 0, ..., 1, 0, 146]])
Nếu sử dụng ma trận như trên sẽ rất khó để nhận biết được ý nghĩa cụ thể của con số đó là gì. Vậy nên, chúng ta sẽ vẽ biểu đồ thể hiện ý nghĩa giữa các con số đó với các label. Trong utility functions đã có sẵn hàm để vẽ confusion matrix này có tên là plot_confusion_matrix(y_true, y_preds, class_names, norm, savefig) với :
+ y_true : label thực của dữ liệu test.
+ y_preds : label được dự đoán cho dữ liệu test.
+ class_names (mặc định là None) : tên label của các class. Nếu không có, nó sẽ tự động chuyển thành số thứ tự.
+ norm (mặc định True) : Liệu có tính tỉ lệ dự đoán hay không.
+ savefig (mặc định False) : có lưu hình ảnh về máy hay không.
plot_confusion_matrix(y_labels, y_pred_labels, class_names)
Tìm top các dự đoán sai trong mô hình.
101 tên class với 25250 hình ảnh dự đoán thực sự tạo một ma trận khổng lồ!!!
Thoạt đầu trông có vẻ hơi khó khăn nhưng sau khi phóng to một chút, chúng ta có thể thấy cách nó cho chúng ta cái nhìn sâu sắc về những lớp nào của nó bị "nhầm lẫn".
Chúng ta có thể thấy đường chéo màu xanh là phần dự đoán chính xác mô hình, nếu ô đó càng đậm màu thì đồng nghĩa có nhiều hình ảnh được đoán đúng. Ngược lại, càng lợt thì càng ít hình ảnh đúng.
Vì chúng ta đang giải quyết vấn đề phân loại, nên có thể đánh giá thêm các dự đoán của mô hình của mình bằng cách sử dụng hàm phân classification_report() của Scikit-Learn.
from sklearn.metrics import classification_report
classification_report_dict = classification_report(y_labels, y_pred_labels, output_dict=True) classification_report_dict
{'0': {'f1-score': 0.22710622710622713, 'precision': 0.20945945945945946, 'recall': 0.248, 'support': 250}, ... 'accuracy': 0.5516435643564357, 'macro avg': {'f1-score': 0.545197670441383, 'precision': 0.5753554804918304, 'recall': 0.5516435643564356, 'support': 25250}, 'weighted avg': {'f1-score': 0.545197670441383, 'precision': 0.5753554804918304, 'recall': 0.5516435643564357, 'support': 25250}}
Trong classification report gồm có : + Precision : Tỷ lệ dương đúng (TP) trên tổng số mẫu. Nếu precision càng cao thì dẫn đến ít dương sai (FP) (mô hình dự đoán 1 khi đáng ra là 0). + Recall : Tỷ lệ dương đúng (TP) trên tổng số dương đúng (TP) và âm sai (FN) (mô hình dự đoán 0 khi lẽ ra là 1). Recall cao hơn dẫn đến ít âm giả. + F1 score : Kết hợp giữa Precision và Recall thành một không gian đo. 1 là tốt nhất, 0 là tệ nhất

Vì F1 score là sự kết hợp của cả 2 phương pháp đánh giá trên, nên chúng ta sẽ lấy F1 để đánh giá cho mô kết quả dự đoán của mô hình thay vì sử dụng cả 3 phương pháp.
classification_f1_score = {} for key, value in classification_report_dict.items() : if key == "accuracy" : break class_name = class_names[int(key)] classification_f1_score[class_name] = value["f1-score"]
import pandas as pd f1_scores = pd.DataFrame({"class_name" : classification_f1_score.keys(), "f1-score" : classification_f1_score.values()}).sort_values(by="f1-score",ascending=False).reset_index(drop=True) f1_scores
| class_name | f1-score | ||||
|---|---|---|---|---|---|
| 0 | edamame | 0.923954 | |||
| 1 | macarons | 0.886510 | |||
| 2 | oysters | 0.830189 | |||
| 3 | dumplings | 0.809339 | |||
| 4 | miso_soup | 0.797595 | |||
| ... | ... | ... | |||
| 96 | tacos | 0.257485 | |||
| 97 | apple_pie | 0.227106 | |||
| 98 | foie_gras | 0.227027 | |||
| 99 | tuna_tartare | 0.225722 | |||
| 100 | steak | 0.184615 |
101 rows × 2 columns
fig, ax = plt.subplots(figsize=(12,30)) scores = ax.barh(f1_scores["class_name"],f1_scores["f1-score"].values) ax.set_yticks(range(len(f1_scores))) ax.set_yticklabels(f1_scores["class_name"]) ax.set_xlabel("posibility") ax.set_ylabel("Label") ax.set_xlim([0,1.1]) ax.invert_yaxis() for rect in scores : x, y = rect.get_width()*1.02, rect.get_y() plt.text(x,y, f"{x:.2f}",ha="left", va="bottom")
Qua biểu đồ trên, chúng ta phần nào có thể thấy được class nào có tỉ lệ dự đoán của mô hình trên từng class với dữ liệu test.
Bây giờ, chúng ta sẽ lập bảng để xem số liệu dự đoán thực tế của các hình ảnh trong dữ liệu test :
Đầu tiên, chúng ta sẽ tạo danh sách đường dẫn đến từng hình ảnh
filepaths = [] for filepath in test_data.list_files("all_food_classes_10_percent/test/*/*.jpg",shuffle=False) : filepaths.append(filepath.numpy().decode("utf-8")) filepaths[:5]
['all_food_classes_10_percent/test/apple_pie/1011328.jpg', 'all_food_classes_10_percent/test/apple_pie/101251.jpg', 'all_food_classes_10_percent/test/apple_pie/1034399.jpg', 'all_food_classes_10_percent/test/apple_pie/103801.jpg', 'all_food_classes_10_percent/test/apple_pie/1038694.jpg']
Để tạo bảng kết quả dự đoán hình ảnh trên dữ liệu test, chúng ta sẽ sử dụng DataFrame trong pandas với các cột sau : + image_path : đường dẫn hình ảnh + y_true : Vị trí thực, + y_pred : Ví trí dự đoán, + pred_conf : xác suất dự đoán cho giá trị cao nhất + y_true_clasname : Tên class thực + y_pred_classname : Tên class dự đoán + result : Kết quả dự đoán
import pandas as pd pred_df = pd.DataFrame({ "image_path" : filepaths, "y_true" : y_labels, "y_pred" : y_pred_labels, "pred_conf" : tf.reduce_max(pred_probs,axis=1), "y_true_classname" : [class_names[i] for i in y_labels], "y_pred_classname" : [class_names[i] for i in y_pred_labels], "result" : y_labels == y_pred_labels }) pred_df
| image_path | y_true | y_pred | pred_conf | y_true_classname | y_pred_classname | result | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | all_food_classes_10_percent/test/apple_pie/101... | 0 | 0 | 0.297717 | apple_pie | apple_pie | True | ||||||||
| 1 | all_food_classes_10_percent/test/apple_pie/101... | 0 | 0 | 0.239391 | apple_pie | apple_pie | True | ||||||||
| ... | ... | ... | ... | ... | ... | ... | ... | ||||||||
| 25248 | all_food_classes_10_percent/test/waffles/97015... | 100 | 93 | 0.208603 | waffles | steak | False | ||||||||
| 25249 | all_food_classes_10_percent/test/waffles/97184... | 100 | 68 | 0.173023 | waffles | onion_rings | False |
25250 rows × 7 columns
OK, bảng kết quả dự đoán đã được tạo. Chúng ta có thể đánh giá khả năng dự đoán bằng cách phân tích, thống kê qua bảng trên.
Top các hình ảnh có xác suất dự đoán cao nhưng lại cho ra kết quả
top_worst_predict = pred_df[pred_df["result"] == False] top_worst_predict.sort_values(by="pred_conf",ascending=False)[:20]
| image_path | y_true | y_pred | pred_conf | y_true_classname | y_pred_classname | result | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 23631 | all_food_classes_10_percent/test/strawberry_sh... | 94 | 83 | 0.991390 | strawberry_shortcake | red_velvet_cake | False | ||||||||
| 23797 | all_food_classes_10_percent/test/sushi/1659357... | 95 | 86 | 0.979919 | sushi | sashimi | False | ||||||||
| 11097 | all_food_classes_10_percent/test/fried_rice/22... | 44 | 70 | 0.977924 | fried_rice | pad_thai | False | ||||||||
| 18935 | all_food_classes_10_percent/test/pho/3741977.jpg | 75 | 33 | 0.969588 | pho | edamame | False | ||||||||
| 22684 | all_food_classes_10_percent/test/spaghetti_bol... | 90 | 91 | 0.931261 | spaghetti_bolognese | spaghetti_carbonara | False | ||||||||
| 14989 | all_food_classes_10_percent/test/lasagna/81697... | 59 | 76 | 0.930435 | lasagna | pizza | False |
Top các label được dự đoán sai nhiều nhất
worst_labels_predict = pred_df.loc[pred_df["y_true"] != pred_df["y_pred"], "y_true_classname"].value_counts()[:20] worst_labels_predict = pd.DataFrame(worst_labels_predict) worst_labels_predict["tỉ lệ sai"] = worst_labels_predict["y_true_classname"] / 750. worst_labels_predict
| y_true_classname | tỉ lệ sai | ||||
|---|---|---|---|---|---|
| steak | 214 | 0.285333 | |||
| nachos | 208 | 0.277333 | |||
| foie_gras | 208 | 0.277333 | |||
| tacos | 207 | 0.276000 | |||
| tuna_tartare | 207 | 0.276000 | |||
| ceviche | 200 | 0.266667 | |||
| ravioli | 200 | 0.266667 | |||
| huevos_rancheros | 195 | 0.260000 | |||
| grilled_cheese_sandwich | 192 | 0.256000 | |||
| crab_cakes | 190 | 0.253333 | |||
| apple_pie | 188 | 0.250667 | |||
| paella | 184 | 0.245333 | |||
| tiramisu | 183 | 0.244000 | |||
| pork_chop | 176 | 0.234667 | |||
| falafel | 169 | 0.225333 | |||
| cheesecake | 168 | 0.224000 | |||
| chocolate_mousse | 168 | 0.224000 | |||
| bruschetta | 168 | 0.224000 | |||
| risotto | 166 | 0.221333 | |||
| beef_tartare | 166 | 0.221333 |
Top các label được dự đoán đúng nhiều nhất
best_labels_predict = pred_df.loc[pred_df["y_true"] == pred_df["y_pred"], "y_true_classname"].value_counts() best_labels_predict = pd.DataFrame(best_labels_predict) best_labels_predict["tỉ lệ"] = best_labels_predict["y_true_classname"] / 750. best_labels_predict
| y_true_classname | tỉ lệ | ||||
|---|---|---|---|---|---|
| edamame | 243 | 0.324000 | |||
| spaghetti_carbonara | 228 | 0.304000 | |||
| hot_and_sour_soup | 224 | 0.298667 | |||
| pizza | 222 | 0.296000 | |||
| pho | 219 | 0.292000 | |||
| ... | ... | ... | |||
| tuna_tartare | 43 | 0.057333 | |||
| tacos | 43 | 0.057333 | |||
| foie_gras | 42 | 0.056000 | |||
| nachos | 42 | 0.056000 | |||
| steak | 36 | 0.048000 |
101 rows × 2 columns
Quan sát giá trị dự đoán và giá trị thực
Để có thể tiến hành dự đoán một hình ảnh nào đó, chúng ta cần biến đổi hình ảnh đó về hình dạng và kiểu giống như những hình đã được train trong mô hình thì mô hình mới có thể hiểu được những gì nó cần làm.
Cụ thể, chúng ta sẽ tạo một hàm để load và xử lý đồng bộ hình ảnh :
- Truyền đường dẫn của hình ảnh đến tensorflow
tf.io.read_file(). - Decode hình ảnh thành các giá trị dưới dạng tensor với
tf.image.decode_image() - Resize lại hình ảnh cho cùng kích thước với hình ảnh được train trong mô hình với
tf.image.resize() - Chuẩn hóa hình ảnh về (0-1) nếu cần thiết.
def load_and_prep_image(image_path, image_shape=(224,224),scale=True) : image = tf.io.read_file(image_path) image = tf.image.decode_image(image,channels=3) image = tf.image.resize(image,size=image_shape) if scale : return image / 255. return image
Hàm load_and_prep_image có nhiệm vụ đưa hình ảnh về hình dạng (height, width, color channel). Mô hình chỉ có thể hiểu dữ liệu qua hình dạng (batch_size, height, width, color channel). Chính vì vậy, chúng ta sẽ tạo thêm 1 chiều cho hình ảnh để nó có số chiều khớp với dữ liệu mô hình học với việc sử dùng tf.expand_dims() để tăng số chiều cho tensor. Nhưng trước hết, chúng ta sẽ tạo hình ảnh ngẫu nhiên để mô hình dự đoán.
Để thực hiện điều này, chúng ta sẽ tạo hàm lấy hình ảnh ngẫu nhiên với mỗi hình đại diện cho 1 class, số lượng mẫu tùy ý nhưng không vượt quá 7. Sau khi hình ảnh ngẫu nhiên, chúng ta sẽ tiến hành dự đoán nó.
import random import os def predict_random_images(model, target_dir, n_samples=1) : if n_samples > 7 or n_samples < 1 : print("Số lượng mẫu không hợp lệ, chỉ có thể từ 1 đến 7") return target_class_names = random.sample(os.listdir(target_dir), k=n_samples) # Tạo vòng lặp để tìm hình ảnh ngẫu nhiên với mỗi class name for class_name in target_class_names : target_class_dir = os.path.join(target_dir, class_name) target_image_name = random.choice(os.listdir(target_class_dir)) target_image_path = os.path.join(target_class_dir, target_image_name) print(target_image_path) # Load hình ảnh và đồng bộ hình ảnh theo chuẩn mực image = load_and_prep_image(target_image_path,scale=False) # Dự đoán hình, chúng ta cần thêm 1 chiều(tại vị trí đầu tiên đại diện cho batch size) để mô hình có thể hiểu được dữ liệu dự đoán image_pred_probs = model.predict(tf.expand_dims(image, axis=0)) # Tạo một DataFrame để lưu tên class name tương ứng với xác suất dự đoán, # Sau đó sắp xếp theo thứ tự giảm dần để xem tỉ lệ dự đoán của mô hình trực quan hơn preds_df = pd.DataFrame({"class_name" : class_names, "probability" : tf.squeeze(image_pred_probs).numpy()}).sort_values(by="probability", ascending=False).reset_index(drop=True) preds_label = preds_df.loc[0,"class_name"] fig, (ax1,ax2) = plt.subplots(1,2,figsize=(20,6)) ax1.imshow(tf.squeeze(image)/255.) if class_name == preds_label : color = "green" else : color = "red" ax1.set_title(f"Actual : {class_name},\n Predict: {preds_label}", color=color) rects = ax2.bar(preds_df["class_name"][:5],preds_df["probability"][:5]) plt.xticks(rotation=90, fontsize=14) for rect in rects : x, w, h = rect.get_x(), rect.get_width(), rect.get_height() plt.text(x+w/2,h,f"{h:.2f}", ha="center", va="bottom", fontsize=14) predict_random_images(model_0, test_dir, n_samples=5)
all_food_classes_10_percent/test/scallops/1844524.jpg all_food_classes_10_percent/test/beet_salad/1100936.jpg all_food_classes_10_percent/test/chicken_quesadilla/173397.jpg all_food_classes_10_percent/test/club_sandwich/3582066.jpg all_food_classes_10_percent/test/churros/1214695.jpg